컨테이너에 대해 공부를 해야겠다는 생각, 그리고 숙제로 미루어 왔던 Control Group에 대해 공부하자는 계획을 세운 뒤 꽤나 오랜 시간이 흘렀습니다. 링크드인의 글을 눈팅하던 중 우연히 “쿠버네티스가 쉬워지는 컨테이너이야기 시리즈” 게시글을 보게 되었고, 해당 글을 바탕으로 공부를 시작했습니다.
앞으로 작성할 cgroup 관련 게시글은 해당 글을 바탕으로 컨테이너에 대한 이해도를 높이고자 작성한 글 입니다.
원글의 출처는 아래와 같습니다.
쿠버네티스가 쉬워지는 컨테이너 이야기 — cgroup, cpu편 (https://medium.com/@7424069/쿠버네티스가-쉬워지는-컨테이너-이야기-cgroup-cpu편-c8f1e2208168), 천강진 님
이 글이 도움 될 사람
- 쿠버네티스가 쉬워지는 컨테이너 이야기 시리즈를 읽었지만 이해가 안되는 부분이 있는 사람
- 컨테이너가 리눅스의 union filesystem, cgroup, namespace를 이용해 만들어지는 것을 알고 있는 사람
- cgroup이 단순히 자원을 격리한다는 것만 알고 있는 사람
본 글의 마지막 부분에는 천강진 님의 이번 글의 대상이 아닌 독자에 대한 개인적인 견해를 작성해 놓았습니다.
컨테이너
컨테이너는 리눅스의 union fs (overlayfs), cgroup, namespace를 이용하여 host os의 메인 워크로드와 격리된 워크로드를 제공하는 가상화 솔루션입니다.
union filesystem을 이용하여 애플리케이션을 실행하기 위한 운영체제 환경부터 시작하여 서비스 바이너리까지 레이어로 나뉘어진 하나의 통합된 파일 시스템을 제공하여 언제 어디서든 동일한 환경을 제공하고 namespace를 이용하여 애플리케이션 프로세스를 격리하여 독립된 환경을 제공할 수 있다면,
control group은 이렇게 격리된 환경, 그리고 언제나 동일한 애플리케이션을 실행하기 위한 리눅스 프로세스 그룹에 시스템 자원을 격리, 할당하여 제어할 수 있도록 해 줍니다.
정리하자면,
- Union Filesystem을 통해 low layer, upper layer, merged view를 통해 레이어화 된 애플리케이션 실행에 필요한 파일시스템을 제공하고
- Namespace를 통해 애플리케이션의 실행 환경을 분리하며
- Control Group을 통해 애플리케이션 실행에 필요한 하드웨어 자원을 격리, 제한하여 독립된 환경에서 안정적으로 실행될 수 있도록 하는 가상화 기술입니다.
“천강진”님의 시리즈를 읽으면서 Control Group을 이해한다면 컨테이너 환경에서의 안정적으로 하드웨어 자원을 제공할 수 있을 뿐 아니라, 애플리케이션에 어떤 현상 혹은 문제가 발생했을 때 조금 더 넓은 각도에서 원인을 분석하고 문제를 해결할 수 있을 것이라 느꼈습니다.
Control Group은 /sys/fs/cgroup 아래에 논리 제어 그룹을 확인할 수 있으며 루트 제어 그룹 아래에 자식 제어 그룹이 존재하는 형태입니다. 새로운 논리 그룹을 생성하려면 대상의 루트, 혹은 자식 제어 그룹에 폴더를 생성하면 됩니다.
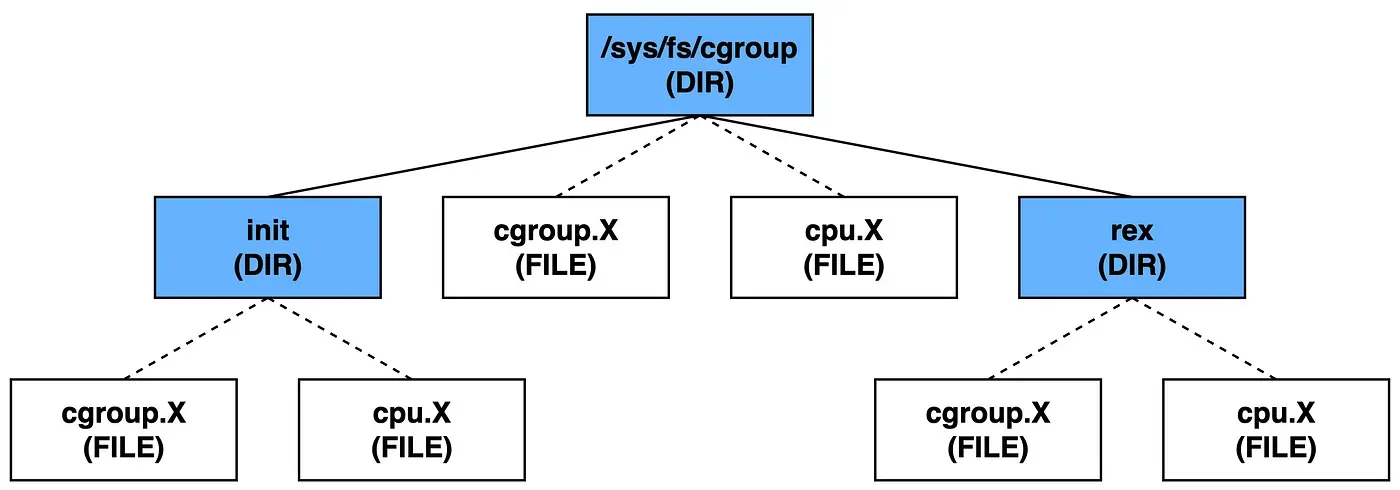
A라는 논리 그룹을 새롭게 만들 경우, 리눅스 시스템에 의해 해당 디렉토리 아래에 자동으로 다음과 같은 구조가 추가됩니다.

단순히 논리 그룹을 만듦으로써 프로세스 격리된 제어 그룹 공간을 활용하는 것은 아닙니다. 생성된 제어 그룹에 실행중인 프로세스의 ID를 할당함으로써 실질적인 제어 그룹을 이용하게 됩니다.

물론 아직 제어 그룹에 대해 자원에 대한 제한을 설정하지 않았기 때문에 아직은 루트 제어 그룹을 그대로 따르는 상태입니다.
Docker의 Control Group과 CPU
잠깐! macOS의 경우 /sys/fs/cgroup을 찾을 수 없습니다. 아래의 명령어를 통해 host의 /sys/fs/cgroup을 확인할 수 있는 컨테이너를 실행해 주세요.
docker run --rm -d -it \
--privileged --pid=host \
--name cgroup-host \
justincormack/nsenter1예제에서 사용된 컨테이너의 경우 아래 명령어로 생성할 수 있습니다.
docker run -d --rm --privileged --name cgroup docker:27.3.1-dind-alpine3.20
도커는 컨테이너를 생성할 때, 하나의 논리 제어 그룹을 생성합니다. 도커를 운영중인 환경에서 /sys/fs/cgroup을 확인해보면 아래와 같이 docker 디렉토리가 존재하는 것을 확인할 수 있습니다.
/sys/fs/cgroup # ls
cgroup.controllers cpu.weight.nice memory.low
cgroup.events cpuset.cpus memory.max
cgroup.freeze cpuset.cpus.effective memory.min
cgroup.kill cpuset.cpus.exclusive memory.oom.group
cgroup.max.depth cpuset.cpus.exclusive.effective memory.peak
cgroup.max.descendants cpuset.cpus.partition memory.reclaim
cgroup.procs cpuset.mems memory.stat
cgroup.stat cpuset.mems.effective memory.swap.current
cgroup.subtree_control **docker** memory.swap.events
cgroup.threads **init.scope** memory.swap.high
cgroup.type io.max memory.swap.max
cpu.idle io.stat memory.swap.peak
cpu.max **k3s** pids.current
cpu.max.burst memory.current pids.events
cpu.stat memory.events pids.events.local
cpu.stat.local memory.events.local pids.max
cpu.weight memory.high pids.peak
/sys/fs/cgroup #
이후 docker 아래의 경로를 확인해보면, 실제로 실행중인 container id 이름으로 제어 그룹이 각각 생성되어 있는것 또한 확인할 수 있습니다.
/sys/fs/cgroup # cd docker
/sys/fs/cgroup/docker # ls
5d16df9b31de84920181fc18e72b4fb5725c9353b3b27f5a758e41cbb039eb54
b1a5dc151e15a4373d30adbc920e8e9ced70e1632d3027c2c4acc55efaeb2395
ba834863df92a0f9919c98e4829d6fb8a4dbdf66e81507f103e75dd710a4c566
cgroup.controllers
cgroup.events
cgroup.freeze
cgroup.kill
cgroup.max.depth
cgroup.max.descendants
cgroup.procs
cgroup.stat
cgroup.subtree_control
cgroup.threads
cgroup.type
cpu.idle
cpu.max
cpu.max.burst
cpu.stat
cpu.stat.local
cpu.weight
cpu.weight.nice
cpuset.cpus
cpuset.cpus.effective
cpuset.cpus.exclusive
cpuset.cpus.exclusive.effective
cpuset.cpus.partition
cpuset.mems
cpuset.mems.effective
e1277fe09be51e878f1b38bb4936982295c68f1f0b0429f9c4ab8319494cc6a5
io.max
io.stat
memory.current
memory.events
memory.events.local
memory.high
memory.low
memory.max
memory.min
memory.oom.group
memory.peak
memory.reclaim
memory.stat
memory.swap.current
memory.swap.events
memory.swap.high
memory.swap.max
memory.swap.peak
pids.current
pids.events
pids.events.local
pids.max
pids.peak
/sys/fs/cgroup/docker #아래는 Host OS에서 docker ps 명령어를 입력했을 때 보이는 컨테이너 입니다.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b1a5dc151e15 justincormack/nsenter1 "/usr/bin/nsenter1" 3 minutes ago Up 3 minutes cgroup-host
e1277fe09be5 docker:27.3.1-dind-alpine3.20 "dockerd-entrypoint.…" 7 minutes ago Up 7 minutes 2375-2376/tcp cgroup
5d16df9b31de mysql:8.0 "docker-entrypoint.s…" 4 days ago Up 7 minutes 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp mysql
ba834863df92 redis:7.4 "docker-entrypoint.s…" 4 days ago Up 7 minutes 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp redis
우리가 생성한 예제의 경우 e1277fe09be5로 실행되고 있는 것을 확인할 수 있으며, 현재 아무 자원 제한을 두지 않았기 때문에 cpu의 max, 가중치를 Host OS에서 확인해 봤을 때 모두 기본 값임을 확인할 수 있습니다.
/sys/fs/cgroup/docker # cat e1277fe*/cpu.weight
100
/sys/fs/cgroup/docker # cat e1277fe*/cpu.max
max 100000
/sys/fs/cgroup/docker # cat e1277fe*/cpu.stat
usage_usec 2073096
user_usec 1489344
system_usec 583751
nr_periods 0
nr_throttled 0
throttled_usec 0
nr_bursts 0
burst_usec 0
컨테이너를 실행할 때 cpu 할당량을 설정한다면 아래와 같은 변화를 확인할 수 있습니다.
$ docker stop cgroup
$ docker run -d --rm --privileged --cpus 0.5 --name cgroup docker:27.3.1-dind-alpine3.20
8292ce42483c59539655d0f727d771cadee933a91c74fe92b53feec96a0b31cd
- 아래 코드는 Host OS에서 실행한 결과입니다.
/sys/fs/cgroup/docker # cat 8292ce*/cpu.weight
100
/sys/fs/cgroup/docker # cat 8292ce*/cpu.max
50000 100000
/sys/fs/cgroup/docker # cat 8292ce*/cpu.stat
usage_usec 1927030
user_usec 1741681
system_usec 185349
nr_periods 113
nr_throttled 35
throttled_usec 1735216
nr_bursts 0
burst_usec 0
control group에서, 다시 말해 컨테이너에서 cpu 자원을 제한한다는 의미는 CPU 스케줄링에 있어서 얼만큼 자원을 선점할 수 있느냐를 의미하는데, 다시 말해 --cpus 0.5를 설정하는 행위는 100ms 동안 50ms를 선점할 수 있다는 것을 의미하게 됩니다.
- 해당 부분이 이해되지 않으신다면, 운영 체제의 CPU 스케줄링에 대해 찾아보시면 좋을것 같습니다.
만약 1개를 넘어가면 어떻게 될까요? 간단하게 하기 위해 cpu 개수를 2로 할당한다면, 다음과 같은 결과가 나오게 됩니다.
$ docker stop cgroup
$ docker run -d --rm --privileged --cpus 2 --name cgroup docker:27.3.1-dind-alpine3.20
68b5952c3487249c14eb48c9649d916475ae7d4593386c9e234d90ba0a92d9f1
---
/sys/fs/cgroup # cd docker
/sys/fs/cgroup/docker # cat 68b5952*/cpu.max
200000 100000
$ docker stop cgroup
$ docker run -d --rm --privileged --cpus 2 --name cgroup docker:27.3.1-dind-alpine3.20
68b5952c3487249c14eb48c9649d916475ae7d4593386c9e234d90ba0a92d9f1
---
/sys/fs/cgroup # cd docker
/sys/fs/cgroup/docker # cat 68b5952*/cpu.max
200000 100000100ms 동안 200ms를 선점할 수 있다는 것이 이상하다 느껴질 수 있습니다.
실제 애플리케이션이 동작하는 환경은 다수의 CPU를 가지는 환경이기 때문에, 단일 CPU의 환경이 아닌 이상 여러 CPU를 통해 각각 100%를 선점하여 200ms를 달성하게 됩니다.
그렇기 때문에 컨테이너 플랫폼 혹은 오케스트레이션 환경에서 cpu 자원을 요청하거나 제한할 때 실제 cpu의 core 수를 넘어서 요청할 수 없게 됩니다.
쿠버네티스의 cpu.weight (cpu.shares)
cpu.weight은 control group을 통해 생성하는 프로세스의 cpu 가중치를 설정할 수 있습니다. 일반적으로 도커, crio 등 컨테이너 플랫폼 환경을 실행한다면 cpu.weight은 일반적으로 100으로 설정되는 것을 확인할 수 있습니다. 이 경우 “천강진”님의 예제를 통해 cpu.weight을 쉽게 이해하실 수 있습니다.
하지만 실제 컨테이너 오케스트레이션 환경(쿠버네티스 등)이나 SaaS, PaaS로 제공되는 환경의 경우 cpu.weight 값이 100으로 설정되어 있지 않는 경우도 있는데, 이 경우 실행하는 서비스 혹은 환경에 의해 cpu.weight 값이 계산되어 할당됩니다. 이는 실제 CPU 리소스를 할당할 때 상대적인 CPU 우선순위를 설정하는 cpu.weight의 특징이자 영향을 받았기 때문입니다.
아래는 온프레미스 환경에 쿠버네티스를 설치하고 제어 그룹 디렉토리로 이동했을 때의 상태입니다. 아직 아무 파드도 설치하지 않았으며, crio v1.31과 쿠버네티스 1.31.2를 설치한 직후의 상태입니다.
root@worker1:/sys/fs/cgroup # ls
A cgroup.procs cpu.pressure dev-hugepages.mount io.cost.qos kubepods.slice misc.capacity sys-kernel-debug.mount
cgroup.controllers cgroup.stat cpu.stat dev-mqueue.mount io.pressure memory.numa_stat proc-sys-fs-binfmt_misc.mount sys-kernel-tracing.mount
cgroup.max.depth cgroup.subtree_control cpuset.cpus.effective init.scope io.prio.class memory.pressure sys-fs-fuse-connections.mount system.slice
cgroup.max.descendants cgroup.threads cpuset.mems.effective io.cost.model io.stat memory.stat sys-kernel-config.mount user.slice
root@worker1:/sys/fs/cgroup # cat kubepods.slice/cpu.weight
79
쿠버네티스의 경우 cpu.weight의 값이 79인 이유는 Control Group V1에서 V2로 넘어오면서 cpu.shares를 cpu.weight로 변환하는 과정에서 스케일링이 발생했기 때문입니다.
- cpu.shares는 실질적으로 가중치를 할당하여 사용한다기 보다 cpu.shares가 설정된 제어 그룹 간의 비율을 바탕으로 CPU 자원을 나눠 사용할 수 있게 됩니다. 즉 cpu.shares가 512, 1024, 2048로 설정되어 있다면, 1:2:4의 비율로 cpu 자원을 할당받아 사용할 수 있게 됩니다. cpu.shares의 최대 값은 2^18 - 2인 262142를 갖습니다.
- control group v1 에서 cpu.shares는 최대 값은 이론상 2^32를 갖지만, 시스템의 안정성 등을 위해 최대 값을 2^18로 제한하고 있습니다.
- 실제로 Ubuntu 등 Linux 계열의 cpu.shares의 옵션을 보면 [2, 262144] 값을 가지고 있습니다.
- 2를 빼는 이유는 cpu.shares의 최소값인 2를 보장하기 위함입니다.
- 512, 1024, 2048 등 vCPU에 대해 Timeslice가 2의 배수로 표현되는 이유는 Linux CFS에서 1024 = default nice 0에 대응하는 값이고, 이를 기본 CPU Weight로 사용하는데 Container의 선구자(?)인 Docker가 이 값을 채택했고 Linux Kernel, CGroup 과 동일하게 유지할 수 있습니다.
- 이러한 cpu.shares를 [1, 10000]의 범위를 갖는 cpu.weight로 변환하기 위해서는 다음의 식이 사용됩니다.
- 1 + ((cpu shares - 2) * [cpu.weight의 맥스 - 최소값] ) / [cpu.shares의 맥스 - 최소값]
- 1 + ((cpu shares - 2) * 9999) / 262142
- 이 때 1을 더해주는 이유는 int 값이기 때문에 버려지는 값을 보완하기 위함입니다.
- cpu.weight 값을 새롭게 스케일링 한 것이 아니라, cpu.shares와 최대한 유사한 값을 제공하기 위한 식입니다.
이를 바탕으로 2 개의 vCPU (CPU 코어)를 갖는 쿠버네티스 환경에서는 1 + (( 2048 - 2 ) * 9999 ) / 262142 값인 79를 도출하게 됩니다.
- 쿠버네티스 관련 코드 → https://github.com/kubernetes/kubernetes/blob/release-1.27/pkg/kubelet/cm/cgroup_manager_linux.go#L312
자 그렇다면 이제 실질적으로 resources.requests.cpu를 설정하여 파드를 배포해서 확인해 봅시다.
apiVersion: v1
kind: Pod
metadata:
name: a
namespace: default
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
resources:
requests:
cpu: 250m
restartPolicy: Always
nodeSelector:
kubernetes.io/hostname: worker1
위 yaml을 바탕으로 pod를 배포하게 되면 cpu.weight의 값은 얼마가 될지 한번 고민해 봅시다.
우리는 전체 CPU shares인 2048에 대해 250m을 요청했고, 2개의 코어를 갖는 노드에서 CPU Weight는 79를 갖고 있습니다. 즉 250 / 2048 만큼 요청했고, 79의 가중치를 갖기 때문에 다음과 같은 식을 갖는다고 예상할 수 있습니다.
1 + 250 / 2048 * 79 ~= 9.6 (10)
이를 직접 워커 노드의 /sys/fs/cgroup을 통해 확인해봅시다.
root@worker1:~# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
**8a6b6f7c79ece 27a71e19c95622dce4d60d4a3760707495c9875f5c5322c5bd535214799593ce 29 minutes ago Running busybox 0 c063f7c199d23 a**
9f61aea39bdf1 registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 fb79be5137b43 coredns-7c65d6cfc9-k65k4
89986ea9962fa registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 220bc9ce4e46f coredns-7c65d6cfc9-hrx2k
f34df68b00d35 registry.k8s.io/kube-proxy@sha256:22535649599e9f22b1b857afcbd9a8b36be238b2b3ea68e47f60bedcea48cd3b 13 hours ago Running kube-proxy 0 90179e9aaf2f6 kube-proxy-mb9f7
root@worker1:~# crictl inspect 8a6b6f7 | grep "pid"
"pid": 16120,
root@worker1:~# find /sys/fs/cgroup -name cgroup.procs -exec grep -H 16120 {} \\;
/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod10e59c76_03e0_447b_bbc0_d66f7ffe0583.slice/crio-8a6b6f7c79ece337d02b1ebdf1fe7984d18c2bb829aa2c75cfed19e18e166fbc.scope/container/cgroup.procs:16120
root@worker1:~# cd /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod10e59c76_03e0_447b_bbc0_d66f7ffe0583.slice/crio-8a6b6f7c79ece337d02b1ebdf1fe7984d18c2bb829aa2c75cfed19e18e166fbc.scope
root@worker1:/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod10e59c76_03e0_447b_bbc0_d66f7ffe0583.slice/crio-8a6b6f7c79ece337d02b1ebdf1fe7984d18c2bb829aa2c75cfed19e18e166fbc.scope# cat cpu.weight
10
우리가 계산한 9.6 + 1 = 10.6에 대한 10의 값이 정상적으로 출력되는 것을 확인할 수 있습니다.
혹시 모르니 resources.requests.cpu를 500m으로 설정하고 다시 확인해 봅시다.
root@master1:~/k8s/pods# cat a.yaml
apiVersion: v1
kind: Pod
metadata:
name: a
namespace: default
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
resources:
requests:
cpu: 500m
restartPolicy: Always
nodeSelector:
kubernetes.io/hostname: worker1
root@master1:~/k8s/pods# kubectl apply -f a.yaml
pod/a created
---
root@worker1:~# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
**1618ac0f6157d 27a71e19c95622dce4d60d4a3760707495c9875f5c5322c5bd535214799593ce 18 seconds ago Running busybox 0 cfbb9f68873cf a**
9f61aea39bdf1 registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 fb79be5137b43 coredns-7c65d6cfc9-k65k4
89986ea9962fa registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 220bc9ce4e46f coredns-7c65d6cfc9-hrx2k
f34df68b00d35 registry.k8s.io/kube-proxy@sha256:22535649599e9f22b1b857afcbd9a8b36be238b2b3ea68e47f60bedcea48cd3b 13 hours ago Running kube-proxy 0 90179e9aaf2f6 kube-proxy-mb9f7
root@worker1:~# crictl inspect 1618ac0f | grep "pid"
"pid": 16906,
"type": "pid"
"pids": {
root@worker1:~# find /sys/fs/cgroup -name cgroup.procs -exec grep -H 16906 {} \\;
/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod089ebf2e_1909_430e_aad6_14f1ff19455b.slice/crio-1618ac0f6157df7b07558d8507856af3a5707cb941ef923786bd8d09ba259b4b.scope/container/cgroup.procs:16906
root@worker1:~# cd /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod089ebf2e_1909_430e_aad6_14f1ff19455b.slice/crio-1618ac0f6157df7b07558d8507856af3a5707cb941ef923786bd8d09ba259b4b.scope
root@worker1:/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod089ebf2e_1909_430e_aad6_14f1ff19455b.slice/crio-1618ac0f6157df7b07558d8507856af3a5707cb941ef923786bd8d09ba259b4b.scope# cat cpu.weight
20
- 예상값: 1 + 500 / 2048 * 79 = 20.28 ( 20 )
- 실제값: 20
- 450m → 18 (17.35 + 1)
이번 글의 대상이 아닌 독자
- k8s는 왜 CPU를 압축 가능한 자원으로 보는가?
- CPU Core에 대한 실행시간, 즉 스케줄링에 대해 가중치를 바탕으로 할당하기 때문에 탄력적으로 조절 가능하기 때문.
- 쿠버네티스에서 CPU requests/limits는 어떤 의미인가?
- CPU requests는 cpu weight을 기반으로 “상대적으로” 컨테이너가 보장받을 수 있는 최소 CPU 자원을 설정한다.
- 예를 들어, 전체 가중치가 100일 때 두 애플리케이션에 각각 50의 가중치가 설정되면, 각 애플리케이션은 최소 50%의 CPU 시간을 보장받는다.
- 하나의 애플리케이션만 존재할 경우, 우리가 알고 있는 스케줄링 정책과 같이 자원을 더 많이 사용할 수 있다.
- 만약 50의 가중치를 가진 애플리케이션이 세 개 존재한다면, 피크 타임에 모두 50%의 CPU를 요청하여 병목 현상이 발생할 수 있다.
- 하지만 쿠버네티스는 스케줄링 정책에서 세 번째 Pod를 Pending 상태로 유지한다.
- 예를 들어, 전체 가중치가 100일 때 두 애플리케이션에 각각 50의 가중치가 설정되면, 각 애플리케이션은 최소 50%의 CPU 시간을 보장받는다.
- CPU limits는 컨테이너가 사용할 수 있는 최대 CPU 시간을 의미한다. CPU 사용량은 이 limits을 초과할 수 없다.
- 그렇기 때문에 쿠버네티스 환경에서는 CPU requests만 설정해도 충분한 경우가 많다.
- 이는 전체 가중치 중 각 애플리케이션의 requests 비율에 따라 CPU 시간이 할당되기 때문이다.
- 따라서 limits을 불필요하게 설정하여 애플리케이션에 인위적인 병목 현상을 만들 필요는 없다.
- 어차피 각 비율에 따라 가질수 있는 최대 CPU 타임은 정해져있다.
- 다만 쿠버네티스의 QoS 정책에 따라 Guaranteed로 사용하기 위해 limits을 설정하는게 좋다.
- CPU requests는 cpu weight을 기반으로 “상대적으로” 컨테이너가 보장받을 수 있는 최소 CPU 자원을 설정한다.
- 컨테이너의 CPU 사용률은 어떻게 측정되는가? ( by 천강진 님 )
/sys/fs/cgroup/C # cat cpu.stat
usage_usec 0 # CPU 총 사용 시간(마이크로초 단위)
user_usec 0 # 사용자 모드에서 실행된 시간
system_usec 0 # 커널 모드에서 실행된 시간
### 아래 값은 cpu.max에 MAX(QUOTA)가 설정된 경우 증가
nr_periods 0 # 스케줄러에 의해 CPU가 할당된 횟수
nr_throttled 0 # 사용 가능한 CPU 시간을 초과 또는 남은 시간이 부족하여 쓰로틀링에 걸린 횟수
throttled_usec 0 # 쓰로틀링 걸린 시간
### 아래 값은 cpu.max.burst가 설정된 경우 증가
nr_bursts 0 # CPU 버스트 모드로 전환된 횟수
burst_usec 0 # 버스트 모드에서 사용한 시간
last_cpu_usage_us = [cpu.stat의 usage_usec]
last_time_us = [현재 시간 마이크로초]
N초 휴식
curr_cpu_usage_us = [cpu.stat의 usage_usec]
curr_time_us = [현재 시간 마이크로초]
delta_cpu_usage_us = curr_cpu_usage_us - last_cpu_usage_us
delta_time_us = curr_time_us - last_time_us
print(f"CPU 사용률: {delta_cpu_usage_us / delta_time_us * 100:.2f}%")
- CPU 사용률이 100%가 아닌데 왜 throttled 상태가 되는가?
- cpu.max에 설정된 CPU 시간을 초과할 수 있기 때문
- 일정량의 RPS 또는 TPS가 목표일 때, 내 어플리케이션에 적용해야할 CPU 값은 어떻게 알 수 있는가?
- 성능 테스트를 통해 CPU 자원 사용량을 계산해야 한 뒤, 목표 값에 도달하기 위해 얼마나 필요할지 예측할 수 있다.
- 예를 들어 1350 RPS가 목표이고, 1000 RPS (TPS)를 처리할 때 0.5 vCPU가 사용되었다면 0.675 vCPU가 필요한 것을 알 수 있다. ( 1350 / 1000 ) * 0.5
- 실제 vCPU를 할당할 때는 이보다 넉넉하게 할당하도록 하자.
- k8s에서 CPU와 관련된 추가 기능은 무엇이 나올 수 있을까?
- 자식 프로세스와 관련된 기능 ?
- address space를 공유할 수 있을것 같고
- CPU의 근본적인 것에 가까워지는 느낌이라, 부모 - 자식 process…….
- 자식 프로세스와 관련된 기능 ?
- 컨테이너 환경은 CPU 활용에 있어 어떤 문제가 있는가?
- Host OS를 이용한다는 점
- 가상 머신의 경우 일반적으로 하드웨어적으로 격리된 자원을 보장받지만
- 컨테이너는 그렇지 않기 때문에 발생할 수 있는
- 자원 이슈
- Host OS를 이용한다는 점
- 7번의 문제는 특정 애플리케이션을 컨테이너로 올리는데 문제가 되는가?
- Host OS에 영향을 줄 수 있는 만큼의 연산을 필요로 하는 애플리케이션
- 우리가 자원량을 설정하지 않는다면 문제가 되지 않을까?
- Host OS에 영향을 줄 수 있는 만큼의 연산을 필요로 하는 애플리케이션
참고
- https://medium.com/@7424069/쿠버네티스가-쉬워지는-컨테이너-이야기-cgroup-cpu편-c8f1e2208168
- https://github.com/kubernetes/kubernetes/blob/release-1.27/pkg/kubelet/cm/cgroup_manager_linux.go#L312
- https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/6/html/resource_management_guide/sec-cpu#sect-cfs
- https://manpages.ubuntu.com/manpages/xenial/en/man5/systemd.resource-control.5.html
'DevOps > Kubernetes' 카테고리의 다른 글
| 네트워크로 시작하는 쿠버네티스 - kube proxy (0) | 2024.12.19 |
|---|---|
| 네트워크로 시작하는 쿠버네티스 - iptables, ipvs, ipip, vxlan (1) | 2024.12.03 |
| 네트워크로 시작하는 쿠버네티스 - 컨테이너 통신, 도커 네트워크 (0) | 2024.11.21 |
| 네트워크로 시작하는 쿠버네티스 - 컨테이너간 통신, Network Namespace (2) | 2024.11.14 |
| 네트워크로 시작하는 쿠버네티스 - 내가 데이터를 보낸다면 (5) | 2024.11.14 |