1. Xcode 설치
2. $ open /Applications/Xcode.app/Contents/Developer/Applications/Simulator.app
1. Xcode 설치
2. $ open /Applications/Xcode.app/Contents/Developer/Applications/Simulator.app
[Java 코딩테스트] 백준 10818 문제풀이 / 배열 없이 최소 최대 구하기
이번엔 백준 10818번 문제를 풀려한다. 이 문제는 굳이 [배열]에 분류되었어야 하나 싶은 문제다. 따라서 배열을 쓰지 않고 푸는 방법, 배열을 쓰고 푸는 방법 총 두 가지로 풀 예정이다. 우선 지금
dev-whoan.xyz
지난 글에 이어서 이번 글은 배열을 이용해 최소 최대를 구할 것이다.
아니 근데 아무생각 없이 Bubble Sort를 이용해서 문제를 풀었더니 시간초과가 발생했다. 아 ㅋㅋ 부끄럽다 ㅋㅋ

아니 근데 ㅋㅋㅋ QuickSort를 했을 때도 시간초과가 발생했다. 이게 무슨일이고!

Merge Sort는 정상적으로 정답이 나오는 것 보니, QuickSort의 최악의 경우가 n^2이라 그런 것 같다. 아마 테스트케이스에 정렬이 거의 다 되어있는 녀석이 있는거겠지.. 휴
여튼! 본론으로 돌아가서 문제풀이를 해 보자.
문제의 내용은 똑같으니, 앞 글에서 확인해주길 바라며 이 글에서는 본의아니게 Merge Sort에 대해 다루겠다
MergeSort, Divide and Conquer
MergeSort, 병합정렬은 쪼개고 합치는 행위로 수행된다.

정렬하고자 하는 배열 혹은 리스트가 주어지면, 더 이상 쪼갤 수 없을 때 까지 쪼갠다. 그리고 나서 다시 합쳐야 하는데, 이 때 더 이상 쪼갤 수 없는 단위까지 쪼갰기 때문에 두 수만 비교하여 정렬하면서 다시 배열을 만들면 된다.

2개를 넘어가는 수에서 합칠때 비교 방법은 다음과 같다.
M번째 요소: 좌측 혹은 우측에서 증가한 자리. 예를 들어, 좌측에서 1번째 요소를 이미 썼다면 M번째 요소는 2번째. 우측도 마찬가지. 이 때, 좌측과 우측의 M번째는 각각 독립적이다.
1. 좌측 배열의 인덱스가 마지막 까지 갔다면, 우측 배열의 M번째 요소를 선택한다.
2. 우측 배열의 인덱스가 마지막 까지 갔다면, 좌측 배열의 M번째 요소를 선택한다.
3. 좌측 배열의 값이 우측 배열의 값보다 작다면 좌측 배열의 M번째 요소를 선택한다.
4. 우측 배열의 값이 좌측 배열의 값보다 작다면 우측 배열의 M번째 요소를 선택한다.
코드를 보면 알겠지만, 각각의 요소를 모두 비교하여 선택하는 방식이다.

이 때, Merge Sort의 복잡도는 O(n logn)이 된다. 이 때, O(n)은 배열 전체에 대한 시간이고, O(log n)은 전체에 대하여 절반으로 나누었기 때문이다.
$$ T(N) = 2 * T(N/2) + N $$ 이고, N/2를 대입하면 $$ T(N/2) = 2 * T(N/4) + {N/2} ... $$가 된다. 반복하여 이를 정리하면, $$ T(N) = 2^n * T( {N / 2^n }) + n*N $$
import java.util.Scanner;
public class Number10818Arr {
public static void main(String args[]){
Scanner scan = new Scanner(System.in);
int N = scan.nextInt();
int arr[] = new int[N];
for(int i = 0; i < N; i++){
arr[i] = scan.nextInt();
}
int arr2[] = new int[N];
sort(arr, 0, N-1, arr2);
System.out.println(arr[0] + " " + arr[N-1]);
}
static void sort(int A[], int low, int high, int B[]){
if(low >= high) return;
int mid = (low + high) / 2;
sort(A, low, mid, B);
sort(A, mid+1, high, B);
int i=low, j=mid+1;
for(int k = low; k <= high; ++k){
if(i > mid)
B[k] = A[j++];
else if(j > high)
B[k] = A[i++];
else if(A[i] <= A[j])
B[k] = A[i++];
else
B[k] = A[j++];
}
for(i = low; i <= high; ++i)
A[i] = B[i];
}
}결과는 정답!

Merge Sort에 관한 글은 새로 정리해서 추가로 올리겠다.
| [자료구조] Java Tree 구현 / 자바 트리 구현 (0) | 2021.06.28 |
|---|---|
| [자료구조] Java Queue 구현 / 자바 큐 구현 (0) | 2021.02.04 |
| [Interface-초급] Java Interface란? / 자바 인터페이스란? (0) | 2021.01.16 |
| [클래스] Java Abstract Class / 자바 추상 클래스 (0) | 2020.12.31 |
| [자료구조] Java Stack 구현 / 자바 스택 구현 (0) | 2020.12.29 |
원래 적어도 이틀에 하나씩 글을 쓰려 했지만, 학기중 스케쥴이 은근 바빠서 실천하지 못했다..ㅠㅠ 여튼! 오늘은 Java Tree 구현법을 보려고 한다.
앞의 ArrayList, Stack, Queue를 모두 본 사람은 알겠지만, 우리는 정보를 담는 어떤 객체와 이 객체를 어떠한 구조를 사용하여 데이터를 저장할 것인가를 다룰 것이다.
트리 구조에서는 흔히 객체를 담는 구조를 노드라고 하며, 이를 가지로 연결하여 나무처럼 만든다 해서 트리라 부른다. 트리에 사용되는 용어는 다음과 같다.
root: 뿌리. 최상위 노드
parent: child node를 갖는 노드
child: parent node를 갖는 노드
edge: 노드를 연결하는 선, branch라고도 함
depth: root부터 어떤 특정 노드까지의 깊이
height: 해당 노드까지 트리의 높이 (level-1)
leaf: 자식이 없는 최말단 노드
degree: 자식 수
아 맞다. 구현하는 글을 쓰고 있었지. 트리의 개념은 따로 정리해서 글을 쓰겠다.
트리는 위에서부터 아래로 만들어 나가는 Top down 방식과 최말단 노드에서부터 위로 올라가는 Bottom Up 방식이 있다. 본 글에서는 탑다운 방식을 구현할 예정이다. Root를 먼저 만들고, 그 뿌리에 가지를 하나씩 이어나가는 방식으로 말이다.
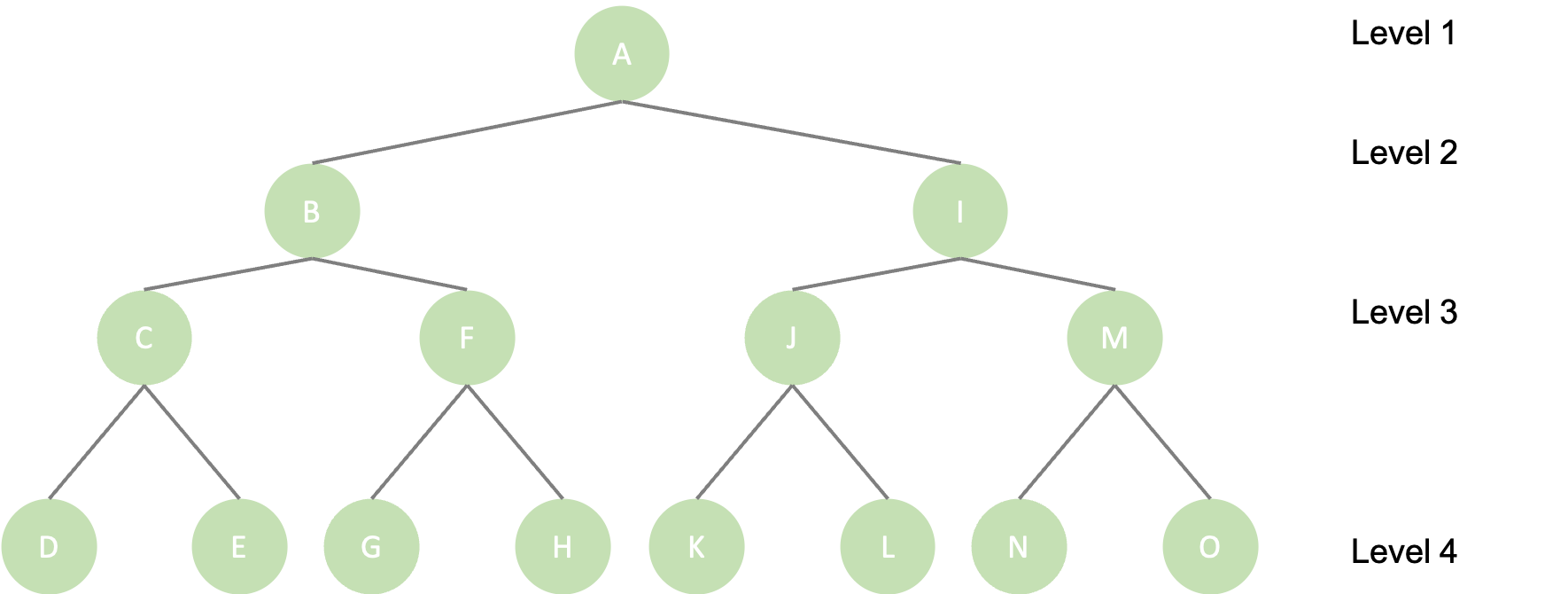
나무(식물)을 떠올려보면, 모두 뿌리를 먼저 내리고 그 이후에 줄기, 기둥, 가지, 잎, 꽃, 그리고 열매를 만들어 나간다.
즉 우리는 먼저 트리의 뿌리, root를 먼저 내려야 한다. 따라서 root를 설정할 수 있어야 하고, 뿌리로부터 나머지 가지들을 칠 수 있어야 한다.
root를 설정하는건 생성자로 할 수도 있고, setRoot와 같은 함수를 통해 할 수도 있다.
가지를 치는 것은 부모에서 자식을 설정하는 것이고, (반대로 자식에서 부모를 찾는 기능이 추가적으로 있어도 된다!) 본 글에서는 이진트리(Binary Tree)를 구현할 예정이라 setLeft, setRight (혹은 addLeft, addRight)를 만들 예정이다.
추가로 있으면 좋을 기능에는 size, height, depth, 그리고 트리의 꽃인 순회 기능이 있다.
본 글에서는 size와 순회기능을 추가 구현하고, 늘 그렇듯 height와 depth는 간단하기 때문에 구현하지 않을 예정이다.
우선 Tree를 책임질 Node를 만들 것이다. Node는 내 부모를 가리킬 수 있어야 하고, 내 자식들을 가리킬 수 있어야 한다.
상상해보라. 나무에서 가지가 끊어진 상태로 존재할수는 없다. 끊어진 나뭇가지는 본체와 아무관계가 없으며, 죽은 가지일 것이다! (마찬가지로 열매도 가지 혹은 꽃으로부터 떨어진다면 더 이상 나무와는 관계 없다.)
노드는 정말 나의 데이터를 설정하고, 부모와 왼쪽, 오른쪽 노드를 가리키는것이 전부이기 때문에 한번에 코드를 올린다.
public class Node<T> {
private T element;
private Node<T> parent;
private Node<T> left;
private Node<T> right;
Node(T element){
this.element = element;
this.parent = null;
this.left = null;
this. right = null;
}
Node(T element, Node<T> left, Node<T> right){
this.element = element;
this.parent = null;
this.left = left;
this.right = right;
}
Node<T> setParent(Node<T> parent){
this.parent = parent;
return this;
}
T getElement(){ return this.element; }
Node<T> setElement(T element){ this.element = element; return this; }
Node<T> getLeft(){ return this.left; }
Node<T> setLeft(Node<T> left){ this.left = left; return this; }
Node<T> getRight(){ return this.right; }
Node<T> setRight(Node<T> right){ this.right = right; return this; }
Node<T> getParent(){ return this.parent;}
}<T>는 제네릭 형태인데, 쉽게 말하면 이 노드는 T형태의 데이터를 갖겠다는 뜻이다. 이 T는 String, int, float 등 아무 객체타입이 될 수 있다.
자 이제 Tree를 구현 해보자! 트리의 생성자는 다음과 같다.
public class Tree<T> {
private Node<T> root;
private int size;
public Tree(){
this(null);
}
public Tree(Node<T> root){
this.root = root;
if(root != null)
size = 1;
}
}나무를 아직 안심었을 수도 있고, 나무를 심었을 수도 있기 때문에 두 가지로 나누었다.
여기에 root, 그리고 트리의 왼쪽, 오른쪽 노드를 설정하는 코드는 다음과 같다.
...
public int size(){ return this.size; }
public Node<T> getRoot(){ return this.root; }
public Tree<T> setRoot(T element){
if(root == null)
size = 1;
this.root = new Node(element);
return this;
}
public Tree<T> setRoot(Node<T> element){
if(root == null)
size = 1;
this.root = element;
return this;
}
public Node<T> addLeft(Node<T> parent, Node<T> child){
if(parent.getLeft() != null){
System.out.println("Already have left");
return null;
}
size++;
parent.setLeft(child);
return parent;
}
public Node<T> addRight(Node<T> parent, Node<T> child){
if(parent.getRight() != null){
System.out.println("Already have right");
return null;
}
size++;
parent.setRight(child);
return parent;
}
public Node<T> removeLeft(Node<T> parent){
Node<T> target = parent.getLeft();
if(target != null)
size--;
parent.setLeft(null);
return target;
}
public Node<T> removeRight(Node<T> parent){
Node<T> target = parent.getRight();
if(target != null)
size--;
parent.setRight(null);
return target;
}
...해당 코드를 보면 root를 설정하거나 획득하는 것을 볼 수 있다.
보면 알겠지만, 트리에서 각 노드들에 대한 왼쪽, 오른쪽 노드를 설정하는 것에 깊게 관여하지 않는다. Node에 기본적으로 왼쪽, 오른쪽을 설정하는 코드가 포함되어 있기 때문에, 노드가 잘 할것이라 믿고 노드에게 준다. 다만, 트리는 이미 자식 노드가 설정되어 있을 때 덮어씌우면 안되기 때문에, 해당 경우에 한해서만 "Already have left!"와 같은 말을 출력해준다.
이제 트리의 꽃인 순회이다. 순회는 크게 3가지 방향이 있다.
height가 1인 full binary tree를 떠올려 보면 다음 표의 왼쪽과 같은 그림이다.

이 트리를 더 확장해보면 아마 오른쪽과 같이 확장 될 것이다. 트리의 모양이 삼각형과 비슷하지 않은가?
자! 삼각형을 한붓 그리기로 그려봐라. 이 때, 각 꼭짓점은 full binary tree의 각 노드를 가리킨다고 하자. 그러면 우리는 이렇게 그릴수 밖에 없다. A-B-C, B-A-C, C-B-A. (각각의 가지수가 더 있지만, 여기까지만 표현하겠다. 그 이유는 다음줄에서 바로 나온다!)
트리의 순회도 똑같다. 부모-왼쪽-오른쪽(부모-오른쪽-왼쪽), 왼쪽-부모-오른쪽(오른쪽-부모-왼쪽), 왼쪽-오른쪽-부모(오른쪽-왼쪽-부모)로 순회할 수 있다. (통상적으로 오른쪽-부모-왼쪽 혹은 오른쪽-왼쪽-부모 의 오른쪽 먼저보다 왼쪽을 먼저 순회한다.)
각각의 순회 방법에 있어서 현재 내 노드(부모)를 기준으로 이름이 붙여지는데, 각각 전위순회, 중위순회, 후위순회라고 부른다(preorder, inorder, postorder).
순회를 할 때 연결된 모든 노드를 순회해야 하며, 이를 재귀를 이용하여 쉽게 나타낼 수 있다.
다시 사진을 보면서 생각해보자! 설명은 preorder만 하고, 나머지 inorder, postorder는 직접 생각해보길 바란다. 원리는 같다.
순회를 A로부터 시작한다고 하자. 그러면 A를 돌고, 왼쪽자식 B, 오른쪽자식 I를 돌아야 한다. 그런데 이 때, B를 순회할 때 또 다시 (부모)-(왼쪽자식)-(오른쪽자식)을 돌아야 하는 상황이 발생하고, B-C-F를 돌게 된다. 마찬가지로 C를 확인할 때 또 다시 C-D-E순으로 돌게 된다. 이후 왼쪽자식이 더 이상 돌 게 없으니, B는 F를 확인하게 된다.
즉, (나)-(왼쪽자식)-(오른쪽자식)을 먼저 돌 때 A-B-C-D-E-F-G-H-I ... 순으로 순회해야하는 것을 알 수 있다.
...
/* traverse */
public void preorder(Node<T> node){
System.out.println(node.getElement());
if(node.getLeft() != null){
preorder(node.getLeft());
}
if(node.getRight() != null){
preorder(node.getRight());
}
}
public void inorder(Node<T> node){
/* Try it! */
}
public void postorder(Node<T> node){
/* Try it! */
}
...트리를 구현할 수 있기 때문에 이제 각 노드에 대해 값이 잘 들어갔는지 확인 하는 코드는 작성하지 않았다.
따라서 최종 실행코드와 결과는 다음과 같다. 노드의 요소를 설정하는 값은 본 글에서 사용한 트리와 같게 했다.
public static void main(String[] args){
Tree<String> tree = new Tree(new Node("A"));
//root node
Node<String> root = tree.getRoot();
tree.addLeft(root, new Node("B"));
tree.addRight(root, new Node("I"));
tree.addLeft(root.getLeft(), new Node("C"));
tree.addRight(root.getLeft(), new Node("F"));
tree.addLeft(root.getRight(), new Node("J"));
tree.addRight(root.getRight(), new Node("M"));
System.out.println("====preorder====");
tree.preorder(root);
System.out.println("\n==== inorder====");
tree.inorder(root);
System.out.println("\n===postorder====");
tree.postorder(root);
System.out.println("\ntree size: " + tree.size());
System.out.println("====remove root.right.left====");
tree.removeLeft(root.getRight());
tree.preorder(root);
System.out.println("\ntree size: " + tree.size());
}
다음 글에서는 그래프 구현 방법을 다룰 예정이다.
끝!
| [Java 코딩테스트] 백준 10818 문제풀이 / 배열 최소 최대 구하기 (0) | 2021.07.22 |
|---|---|
| [자료구조] Java Queue 구현 / 자바 큐 구현 (0) | 2021.02.04 |
| [Interface-초급] Java Interface란? / 자바 인터페이스란? (0) | 2021.01.16 |
| [클래스] Java Abstract Class / 자바 추상 클래스 (0) | 2020.12.31 |
| [자료구조] Java Stack 구현 / 자바 스택 구현 (0) | 2020.12.29 |
이번엔 Queue와 관련된 자료구조에 대해 공부하려고 한다.
Queue는 Stack과는 반대로, FIFO(First In First Out)성질을 갖는다. 즉 먼저 들어온 녀석이 먼저 나간다.
Queue의 가장 흔한 예시로는 프린트 출력 대기열을 들 수 있는데, 먼저 출력 요청한 문서를 먼저 출력해야 하기 때문이다. 비슷한 예로 입장 대기줄 등이 있다.
큐는 탐색에서도 스택과 함께 많이 쓰이므로 잘 알아두면 좋다. 특히 큐는 우선순위 큐, 원형 큐 ... 등 많은 종류가 있기 때문에, 기본 큐는 반드시 알아야 한다.

Queue는 Stack과 비슷한 자료구조로, 데이터를 삽입하고 반환할 수 있어야 한다. Stack처럼 제일 위에 삽입한다고 생각해도 된다. 다만 Stack과의 차이점은 시작점과 끝점이 있어야 한다는 것이다. Stack은 top이라는 시작점만 존재했지만, Queue는 끝점도 가져야하는 이유는 다음과 같다.
1. 제일 먼저 들어온 녀석을 반환하기 위함
2. 큐가 가득 찼는지 확인하기 위함.
즉 Queue에도 Top만 존재했다면, 어느 녀석을 먼저 반환해야 할지, 새로 들어온 녀석은 어디로 들어와야 할지를 동시에 수행할 수 없기 때문에 끝점도 존재해야 하는 것이다.
그렇다면 rear는 어떻게 활용할 수 있을까? Queue에 데이터가 삽입되면 rear가 하나씩 증가하게 된다. 이를 조금 더 생각 해 보면, front와 rear가 같다면, Queue가 비어있는 상황이 되고, rear가 capacity와 같아지게 되면 Queue가 가득차게 되는 것이다.
따라서 Queue는 front, rear, capacity 그리고 queue를 담는 배열이 필요하다.
Queue의 기본은 다음과 같다.
public class Queue {
int front;
int rear;
int capacity;
Object[] queue;
Queue(int capacity){
this.front = -1;
this.rear = -1;
this.capacity = capacity;
queue = new Object[this.capacity];
}
public boolean isFull() {
/*
capacity가 10이면 배열은 0~9를 갖고, rear도 0부터 시작하기 때문에 -1을 해야한다.
*/
return (this.rear == this.capacity-1);
}
public boolean isEmpty() {
/*
front와 rear가 같으면 비어있는 상태이기 때문에, 편의를 위해 front와 rear를 -1로 초기화 시켜준다.
*/
if(front == rear) {
front = -1;
rear = -1;
}
return (this.front == this.rear);
}
}다음으로 Queue에 데이터를 삽입하고 반환하는 함수가 필요한데, Stack에서는 이를 pop, push라고 했다면 Queue에서는 enqueue, dequeue라고 한다.
데이터를 반환하기 위해서는 front에 있는 먼저 들어온 녀석을 반환해줘야 하는데, 반환 해줄 때 마다 front의 위치를 옮겨주어야 한다.

위 그림을 보면, 다음 출력 문서의 위치 front는 고정되어 있고, 남아있는 문서들을 한칸씩 옮기는 오른쪽 그림과 다음 출력 문서의 위치 front를 이동시키고 남아있는 문서들은 고정되어 있는 왼쪽 그림중 어느 것이 더 편해 보이겠는가?
정답은 당연히 왼쪽 그림인 front를 옮기는게 훨씬 간단하다.
이렇게 dequeue에서 front를 옮기기 때문에, rear의 위치 또한 단순히 배열의 index를 옮겨서는 안되고, 한가지 트릭을 써야 한다. (만약 n칸짜리 queue에서 n개를 넣고 dequeue를 n번 하면, front와 rear의 크기는 같아지게 된다. 즉 queue는 비어있게 되는데, 문제는 rear의 위치가 capacity와 같아지기 때문에 동시에 가득찬 상황이 된다. 이는 Queue의 모순이지 않는가?)
rear에 사용할 트릭은, 단순히 index를 지정하는 게 아니라 Queue의 capacity로 나누어서 나온 몫이 rear의 index가 되게 해야 한다. 위 괄호안에서 든 예시로 말하자면, capacity가 10이라고 가정 했을 때, rear와 front는 모두 9가 되는 상황이다. 이 때, (rear+1) % (capacity = 10) 을 하면 삽입할 다음 index는 0이 되고, rear와 front의 차이는 다시금 10이 되기 때문에 처음부터 넣는것과 같게 된다. (+1을 해주는 이유는, 삽입할 element는 다음 번 index를 가져야 하기 때문이다.)
이를 바탕으로 enqueue를 설계하면 다음과 같다.
public class Queue {
...
public void enqueue(Object element) {
if(isFull()) {
System.out.println("Queue is Full!");
return;
}
rear = (rear+1) % this.capacity;
queue[rear] = element;
}
...
}
dequeue 또한 enqueue와 같은 원리로 Queue의 capacity로 나눈 몫을 index로 가지면 된다. 이유는 위에서 rear에 대한 설명한 것과 같다.
public class Queue {
...
public Object dequeue() {
if(isEmpty()) {
System.out.println("Queue is empty");
return null;
}
front = (front+1) % this.capacity;
return queue[front];
}
...
}Queue도 Stack과 같이 element를 반환하지 않고 엿보는 peek을 가질 수 있는데, 코드는 다음과 같다.
public class Queue {
...
public Object peek() {
if(isEmpty()) {
System.out.println("Queue is empty");
return null;
}
return queue[front+1];
}
...
}
이제 queue의 size와 초기화를 시켜주는 함수를 만들면 된다.
size는 rear - front를 통해 구할 수 있다. 이는 내가 마지막으로 삽입한 index - 제일 먼저 삽입한 index가 되고, 5개 입력했으면 다음과 같기 때문이다 (5-0) = 5. 그런데 배열은 0부터 시작하기 때문에 front와 rear에 각각 1씩 더해주면 된다. ( (4+1) - (-1+1) ) = 5. 또한 Queue는 front와 rear의 index가 역전될 수 있으니, 절대값 으로 반환하면 된다.
초기화는 간단하게 front, rear, 모두 -1로, 그리고 queue 배열을 새로 선언하면 된다.
코드는 다음과 같다.
public class Queue {
...
public int size() {
return Math.abs( (rear+1) - (front+1) );
}
public void clear() {
if(isEmpty()) {
System.out.println("Queue is already empty!");
}
else {
front = -1;
rear = -1;
queue = new Object[this.capacity];
System.out.println("Queue has cleared!");
}
}
}
public class Queue {
int front;
int rear;
int capacity;
Object[] queue;
Queue(int capacity){
this.front = -1;
this.rear = -1;
this.capacity = capacity;
queue = new Object[this.capacity];
}
public boolean isFull() {
return (this.rear == this.capacity-1);
}
public boolean isEmpty() {
if(front == rear) {
front = -1;
rear = -1;
}
return (this.front == this.rear);
}
public void enqueue(Object element) {
if(isFull()) {
System.out.println("Queue is Full!");
return;
}
rear = (rear+1) % this.capacity;
queue[rear] = element;
}
public Object dequeue() {
if(isEmpty()) {
System.out.println("Queue is empty");
return null;
}
front = (front+1) % this.capacity;
return queue[front];
}
public Object peek() {
if(isEmpty()) {
System.out.println("Queue is empty");
return null;
}
return queue[front+1];
}
public int size() {
return Math.abs( (rear+1) - (front+1) );
}
public void clear() {
if(isEmpty()) {
System.out.println("Queue is already empty!");
}
else {
front = -1;
rear = -1;
queue = new Object[this.capacity];
System.out.println("Queue has cleared!");
}
}
}아래는 실행코드이다.
public class mainQueue {
public static void main(String[] args) {
System.out.println("=====짧은머리 개발자=====");
Queue queue = new Queue(10);
queue.dequeue();
for(int i = 0; i < 10; i++) {
queue.enqueue(i);
}
System.out.println("isFull : " + queue.isFull());
System.out.println("size : " + queue.size());
for(int i = 0; i < 10; i++) {
System.out.println("Dequeue : " + queue.dequeue());
System.out.println("size : " + queue.size());
}
System.out.println("Dequeue : " + queue.dequeue());
System.out.println("isEmpty : " + queue.isEmpty());
queue.enqueue(555);
System.out.println("isEmpty : " + queue.isEmpty());
System.out.println("isFull : " + queue.isFull());
System.out.println("peek: " + queue.peek());
}
}실행 결과

제네릭은 일부러 안했다. 여러분이 한번 해보세요! 쉬워요.
| [Java 코딩테스트] 백준 10818 문제풀이 / 배열 최소 최대 구하기 (0) | 2021.07.22 |
|---|---|
| [자료구조] Java Tree 구현 / 자바 트리 구현 (0) | 2021.06.28 |
| [Interface-초급] Java Interface란? / 자바 인터페이스란? (0) | 2021.01.16 |
| [클래스] Java Abstract Class / 자바 추상 클래스 (0) | 2020.12.31 |
| [자료구조] Java Stack 구현 / 자바 스택 구현 (0) | 2020.12.29 |
[클래스] Abstract Class / 추상 클래스
Java는 클래스를 중심으로 객체들을 설계하는 언어이다. 바꿔 말하면 문제를 해결하기 위해 클래스를 설계하고, 이를 인스턴스화 하여 사용한다. 또한 Java를 사용할 때 의 장점 중(객체지향 프로
dev-whoan.xyz
인터페이스를 한 단어로 표현하면 '규약'이다. 개발하면서 꼭 지켜야 할 '규약'같은 존재로, 바꿔말하면 개발할 때 반드시 포함해야하는 멤버를 모아놓은것이 인터페이스다.
이렇게 말하면, 추상 클래스와 다른점이 무엇인지 헷갈릴 수 있다.
추상 클래스는 쉽게 말해 개발이 들어간 시점에서 공통된 속성을 모아놓은 클래스이며, 해당 추상 클래스를 '상속'하는 클래스는 해당 추상 메소드들을 모두 구현하여야 한다.
인터페이스는 이와 다르게 개발이 들어가기 전에 만들어질 메소드들에 대해 '규칙'을 정해놓은 것이고, 이를 '구현'하는 클래스들은 해당 메소드들을 모두 내용을 담아 만들어야 한다.
아직까지 이해가 안되는가?
그렇다면 경우를 들어 설명해 보자면, A와 B가 함께 자동차 객체를 생성하는 클래스를 만든다고 하자. 이 때, A는 자동차의 구동을 담당하고, B는 자동차의 프레임을 담당한다고 하자.
결국 자동차는 프레임과 구동부가 결합되어야 하는데, 만약 결합부가 일치하지 않는다면 설계에 실패했다고 볼 수 있고, 즉 자동차 객체를 생성 못한다고 볼 수 있다.
이를 위해 결합부에 대해 어떻게 설계하겠다는 약속을 정해야 하는데, 이를 인터페이스를 이용해 약속하는 것이다.
인터페이스는 이렇게 생겼다.
interface CarInterface{
public void move();
public void setSpeed(int speed);
}CarInterface는 move와 setSpeed에 대해 설계 방식을 정하고 있고, 해당 인터페이스를 구현하는 클래스들은 두 함수에 대해 실질적인 내용을 담아야한다.
즉, 인터페이스는 함수내부가 어떻게 생겼을 지 모르겠지만, return 타입, 받아들일 파라미터 등 함수가 어떻게 생겼는지를 정해놓은 것이다.
따라서 A와 B가 같은 자동차를 설계하기 전에 인터페이스를 만들어 놓고, 결합부에 대해 약속을 정한다면 결합부가 일치하지 않아 자동차를 만들 수 없는 일은 발생하지 않을것이다.
인터페이스가 가지는 추상클래스와의 가장 큰 다른점은 재사용성이다. 클래스는 다중상속이 불가능하지만, 인터페이스는 다중상속이 가능하다.
interface Vehicle{
public void move();
}
interface WheelObjects{
public void setWheels();
public void getWheels();
}
interface Car extends Vehicle, WheelObjects{
public void setHorsePower(float horsePower);
}
interface Airplane extends Vehicle{
public void setMaha(float Maha);
}위와 같은 다중상속이 가능해짐으로써, Car라는 인터페이스를 만들기 위해 Vehicle과 WheelObjects의 인터페이스를 상속받아 각 인터페이스가 갖는 규칙을 모두 가질 수 있는 것이다.
뿐만 아니라, Vehicle 인터페이스를 Car에만 사용하는 것이 아니라 Airplane이라는 움직이는 방법이 전혀 다른 이동수단이 상속받을 수 있게 설계할 수 있다.
만약 추상클래스였다면, Car가 갖는 속성들을 Airplane은 가질수 없는게 당연한것과는 반대되는 성질이다.
Java 8이 넘어가면서 추상클래스와 인터페이스의 관계는 많이 모호해지긴 했지만, 인터페이스의 특징을 잘 살리면 인터페이스 나름의 이용성이 큰 녀석이기 때문에 잘 이해해두면 좋은 친구다.
| [자료구조] Java Tree 구현 / 자바 트리 구현 (0) | 2021.06.28 |
|---|---|
| [자료구조] Java Queue 구현 / 자바 큐 구현 (0) | 2021.02.04 |
| [클래스] Java Abstract Class / 자바 추상 클래스 (0) | 2020.12.31 |
| [자료구조] Java Stack 구현 / 자바 스택 구현 (0) | 2020.12.29 |
| [자료구조] Java ArrayList 구현 / 자바 리스트 구현 (0) | 2020.12.27 |
Java는 클래스를 중심으로 객체들을 설계하는 언어이다. 바꿔 말하면 문제를 해결하기 위해 클래스를 설계하고, 이를 인스턴스화 하여 사용한다.
또한 Java를 사용할 때 의 장점 중(객체지향 프로그래밍의 장점 중) 재사용성이 있는데, 이는 다음과 같이 해석할 수도 있다.
'비슷한 형태를 묶어 하나의 클래스를 만들고, 그 클래스로부터 각각의 문제를 해결한다.'
즉, 클래스의 구현과 사용을 분리하여 만드는 것이 일반적이다. 만약 현대자동차를 만드는 클래스 하나, 기아자동차를 만드는 클래스 하나와 같이 같은 형태의 문제를 각각의 클래스를 만들면 낭비이고 비효율을 초래한다.
여기까지 이해하면 다음과 같이 설계할 수 있다.
class Car{
String company;
String name;
int speed;
Car(String company; String name, int speed){
this.company = company;
this.name = name;
this.speed = speed;
}
public void move(){
this.speed = 100;
System.out.println(this.company + "의 " + this.name + "가 " + this.speed + "의 속도로 달립니다.");
}
public void stop(){
this.speed = 0;
System.out.println(this.company + "의 " + this.name + "가 " + this.speed + "의 속도로 달립니다.");
}
}<이는 정말 간단한 예를 표현하기 위한것이니 왜 이렇게 짰는지는 묻지 말아주길 바란다.>
그런데, 위에서 말했듯이, 클래스의 구현과 사용은 분리하는것이 좋다. 위의 예는 클래스의 '사용'을 나타낸 것이다.
이를 어떻게 구현과 사용으로 분리할 수 있을까?
구현은 Abstract(추상화) 사용은 Extends(상속)
abstract의 사전적 의미는 추상이다. 추상의 국어사전 속 의미는
추상1 (抽象) [명사] [심리 ] 여러 가지 사물이나 개념에서 공통되는 특성이나 속성 따위를 추출하여 파악하는 작용.
<출처: 네이버 국어사전>
이를 프로그래밍 관점에서 보자면, "객체들에 대해 공통적인 속성을 추상화 시켜놓고 해당 속성을 각각의 Class에서 구현하고 사용한다."로 생각하면 된다.
자동차로 예를 들면, 쉽게 자동차는 굴러가고, 멈춘다. 그런데 각각의 자동차가 어떤 속도로 굴러갈지, 어떻게 멈출지는 모르는 법이다. 따라서 위에서 만들었던 Car class에서 move와 stop을 추상화하면 된다.
Java에서 추상화 하는 방식은 abstract한정자를 사용하면 된다. 또한 abstract한정자를 갖는 클래스는 abstract class, 즉 추상 클래스가 된다.
우리는 각각의 자동차가 어떻게 굴러가는지, 또 어떻게 멈추는지 모른다. 즉 추상화하고자 하는 method의 동작 방식을 전혀 모른다. 따라서 abstract method는 본문 내용을 가져서는 안된다. 즉, 다음과 같이 표현하여야 한다
abstract public void move(); (단, 우리는 동작방식이 어떻게 될지 모르는거지, 인자로 뭐가 들어올지는 설정할 수 있다. 가령, 움직이는 속도를 전달받는다 하면 abstract public void move(int speed);와 같이 나타내면 된다.)
그러면 실제로는 어떻게 해야할까?
앞선 내용을 바탕으로 구현과 사용을 분리해 보면, 다음과 같이 나타낼 수 있다.
public abstract class CarFrame{
int speed;
String name;
String company;
abstract public void move();
abstract public void stop();
public void Status(){
System.out.println(this.company + "의 " + this.name + " 현재 속도: " + this.speed);
}
public int getSpeed() { return this.speed; }
public String getName() { return this.name; }
public String getCompany() { return this.company; }
public void setSpeed(int speed) { this.speed = speed; }
public void setName(String name) { this.name = name; }
public void setCompany(String company) { this.company = company; }
}
public class Car extends CarFrame{
public Car(String name, String company){
setSpeed(0);
setName(name);
setCompany(company);
}
public void move(){ setSpeed(100); }
public void stop(){ setSpeed(0); }
}
public class mainAbstract {
public static void main(String[] args) {
Car Sportage = new Car("스포티지", "기아자동차");
Car Tucson = new Car("투싼", "현대자동차");
Sportage.Status();
Tucson.Status();
/*****************************/
Sportage.move();
Tucson.move();
Sportage.Status();
Tucson.Status();
/*****************************/
Sportage.stop();
Tucson.stop();
Sportage.Status();
Tucson.Status();
}
}CarFarme이라는 abstract class, 추상 클래스를 통해 자동차들에 대해 하나로 구현하였고, 각각의 자동차에 대해 Car라는 class를 인스턴스화 함으로써 사용하게 하였다. (이때 getter와 setter를 사용하지 않고 직접 변수 getter setter를 사용하고 싶으면 CarFrame의 변수들에 대해 접근제한자를 바꿔주면 된다.)
아래의 maniAbstract 클래스를 실행하면 다음과 같은 결과가 나온다.

앞에서 우리가 사용할 때 공통적인 내용을 추상화 했다. 프로그래밍을 시작한지 얼마 안된 사람이라면 다음과 같은 의문을 가질 수 있다.
"어? 그러면 쉐보레와 현대/기아가 있을때, 현대/기아만 갖는 속성은 어떻게 나타낼 수 있어요?"
우리는 현대 자동차와 기아 자동차가 같은 내용을 가진다고 가정 했다. (같은 그룹이라서..)
이는 우리가 Car를 상속받아 현대자동차 클래스 / 쉐보레 클래스를 각각 구현하여, 해당하는 클래스에 멤버변수나 메소드를 추가해주면 된다.
그러한 예를 나타내고 상속클래스 게시글을 마치겠다.
전방충돌감지 레이더를 장착한 기아 자동차의 스포티지와 깡통 옵션으로 출고된 트래버스를 구현할 때, 다음처럼 구현할 수 있다.
쉐보레를 싫어하는게 아니라 구현의 귀찮음으로 인해 스포티지만 전방인식 레이더가 있다고 구현했습니다.
public class Kia extends Car{
int frontObject = -1;
public Kia(String name, String company) { super(name, company); this.frontObject = -1;}
public void frontObject(int distance) {
this.frontObject = distance;
}
@Override
public void move() {
if(frontObject > 0) {
super.setSpeed(100 - frontObject);
}else {
super.setSpeed(100);
}
if(super.getSpeed() < 30) {
System.out.println("전방 충돌 주의!!! 긴급제동을 시작합니다.");
super.setSpeed(0);
}
}
}
public class Chevrolet extends Car{
public Chevrolet(String name, String company) { super(name, company); }
}
public class mainAbstract {
public static void main(String[] args) {
System.out.println("=====짧은머리 개발자=====");
Kia Sportage = new Kia("스포티지", "기아자동차");
Chevrolet Traverse = new Chevrolet("트래버스", "쉐보레");
Sportage.move();
Traverse.move();
Sportage.Status();
Traverse.Status();
System.out.println("===50m 전방 사람===");
Sportage.frontObject(50);
Sportage.move();
Sportage.Status();
System.out.println("===30m 전방 사람===");
Sportage.frontObject(70);
Sportage.move();
Sportage.Status();
System.out.println("===20m 전방 사람===");
Sportage.frontObject(80);
Sportage.move();
Sportage.Status();
}
}
Chevrolet Class는 frontObject라는게 없기 때문에 Traverse.frontObject를 사용할 수 없어서 Sportage에만 사용하였습니다.
| [자료구조] Java Tree 구현 / 자바 트리 구현 (0) | 2021.06.28 |
|---|---|
| [자료구조] Java Queue 구현 / 자바 큐 구현 (0) | 2021.02.04 |
| [Interface-초급] Java Interface란? / 자바 인터페이스란? (0) | 2021.01.16 |
| [자료구조] Java Stack 구현 / 자바 스택 구현 (0) | 2020.12.29 |
| [자료구조] Java ArrayList 구현 / 자바 리스트 구현 (0) | 2020.12.27 |
[자료구조] Java ArrayList 구현
ArrayList는 크기가 고정되지않은, 즉 동적 배열을 의미한다. 배열(Array)와의 차이점으로 배열은 초기화할 때 크기를 지정해야 하지만, ArrayList는 그러지 않아도 된다. 즉 배열은 고정값의 크기를 가
dev-whoan.xyz
모든 데이터 및 알고리즘을 List 구조만 이용해서 최적화된 프로그래밍을 할 수 있으면 얼마나좋을까?
안타깝게도 그렇지 않기 때문에 세상에는 List를 제외한 많은 자료구조가 존재한다.
이번에는 Stack과 관련된 구현을 할 예정이다
Stack은 Last In First Out 구조를 갖는다. 이 LIFO 구조를 갖는 가장 흔한 예를 들어보면 많이 원기둥으로 된 초콜릿 통을 얘기한다. 하지만 우리 프로그래밍 세계에는 초콜릿 통만 만들지 않으니, 다른 예를 알아볼 필요도 있다.
이런 예는 어떨까?
구조선에 총 500kg의 인원을 태울 수 있다. 구조를 기다리는 사람들은 차례로 줄 서서 탑승을 기다리고 있다. 구조선이 도착지에 도착하면, 탑승구에 있는 사람부터 내린다. 구조선은 총 탑승 중량이 500kg을 넘어가면, 출발한지 조금 지나 침몰한다. 탑승할 때, 중량을 나타내는 전자저울이 있다.

해당 문제는 도착지에 도착하건, 중량초과를 하건, 제일 마지막에 탑승한 사람부터 내려야 한다. 이러한 경우 Stack을 이용해 구현할 수 있겠다.
Stack은 Last In First Out
Stack에 대해 이미지를 연상해보면 다음과 같이 생각하면 편하다.

즉, 제일 위에서(top) 데이터를 삽입하거나, 데이터를 반환한다.
stack은 리스트처럼 1. 크기가 고정(배열) 2. 크기가 동적(ArrayList)의 성격을 가질 수 있고, 구현 방법은 그 성격과 같다.
크기를 고정시키고 싶다면 배열로 구현하고, 크기를 동적으로 변경하고 싶다면 ArrayList로 구현하면 된다. 오늘 게시글에서는 크기가 고정된 Stack을 구현해 보겠다.
Stack에는 어떤게 필요할까?
Stack은 어떤 기능이 필요할까? 기본적인 목적은 제일 위에서 데이터를 삽입, 반환할 수 있어야 한다. 부가적으로, 현재 Stack의 사이즈와 크기, 초기화, 그리고 비어있거나 꽉찼는지를 구할 수 있으면 된다.
따라서 제일 위를 구하는 top, 크기를 담는 capacity를 가지면 된다.
Stack에서는 ArrayList와 달리 add, remove라는 함수 이름을 사용하지 않고 각각 push, pop이라는 이름의 함수를 사용한다.
Stack 구현
따라서 Stack의 기본은 다음과 같다.
public class Stack<T> {
int top;
int capacity = -1;
T[] stack;
Stack(int capacity){
this.capacity = capacity;
stack = (T[]) (new Object[capacity]);
top = -1;
}
}top을 -1로 초기화 하는 이유는 개발의 간편함을 위함이다. 따라서 스택이 비어있을때 top은 -1이 된다.
고정된 크기를 갖는 Stack을 구현하기 생성자는 capacity값을 전달해야 한다.
데이터를 삽입할 때는 Stack이 가득찼는지 확인해야 한다. 그리고 공간이 남아있다면 데이터를 삽입하면 된다.
public class Stack<T> {
...
public void push(T element) {
if(isFull()) {
System.out.println("Stack이 가득 찼습니다.");
return;
}
stack[++top] = element;
}
public boolean isFull() { return (this.top == this.capacity-1); }
...
}isFull(): 스택이 가득찼는지 확인한다.
데이터를 반환할 때는 삽입할 때와 반대로 Stack이 비어있는지 확인해야 한다. 그리고 비어있지 않다면 데이터를 반환하면 된다.
public class Stack<T> {
...
public T pop() {
if(isEmpty()) {
System.out.println("Stack이 비어있습니다.");
return null;
}
return stack[top--];
}
public boolean isEmpty() { return (this.top == -1); }
...
}isEmpty(): 스택이 비어있는지 확인한다.
그런데 우리는 반환하지 않고 데이터를 확인만 하고 싶을수도 있다. 이럴 때를 위해 peek()라는 함수가 존재한다. 이는 stack에서 데이터를 삭제하지 않고, top에 어떤 data가 존재하는지 확인을 가능하게 한다.
public class Stack<T> {
...
public T peek() {
if(isEmpty()) {
System.out.println("Stack이 비어있습니다.");
return null;
}
return stack[top];
}
public boolean isEmpty() { return (this.top == -1); }
...
}pop과의 차이점은 return (T) stack[top--]; 과 return (T) stack[top]; 이다.
pop의 경우 top을 하나 감소시켜 다음 데이터가 삽입될때, 반환한 데이터 위치에 새로운 데이터가 덮어씌워지지만, peek의 경우 top의 데이터 조작을 일체 하지 않음으로써 다음 pop 혹은 push를 수행할 때 기존과 같은 역활을 하게 하는 것이다.
이제 나머지 부가기능인 stack의 크기와 초기화 하는 함수를 만들어주면 된다.
public class Stack<T> {
...
public void clear(){
if(isEmpty()){
System.out.println("Stack은 이미 비어있습니다.");
return;
}
top = -1;
stack = (T[]) (new Object[capacity]);
System.out.println("Stack 초기화 완료!");
}
public int size(){
return (top+1);
}
}
전체코드와 실행 결과
public class mainStack {
public static void main(String[] args) {
System.out.println("=====짧은머리 개발자=====");
Stack<Integer> stack = new Stack<>(5);
for(int i = 0; i < 5; i++) {
stack.push((i+1));
System.out.println(i + " 번째 peek: " + stack.peek());
}
System.out.println("===Pop===");
for(int i = stack.size(); i > 0; i--) {
System.out.print(i + " 번째 : " + stack.pop() + " | " );
}
}
}
public class Stack<T> {
int top;
int capacity = -1;
T[] stack;
public Stack(int capacity){
this.capacity = capacity;
stack = (T[]) (new Object[capacity]);
System.out.println("size : " + capacity);
top = -1;
}
public void push(T element) {
if(isFull()) {
System.out.println("Stack이 가득 찼습니다.");
return;
}
stack[++top] = element;
}
public T pop() {
if(isEmpty()) {
System.out.println("Stack이 비어있습니다.");
return null;
}
return stack[top--];
}
public T peek() {
if(isEmpty()) {
System.out.println("Stack이 비어있습니다.");
return null;
}
return stack[top];
}
public void clear(){
if(isEmpty()){
System.out.println("Stack은 이미 비어있습니다.");
return;
}
top = 0;
stack = (T[]) (new Object[capacity]);
System.out.println("Stack 초기화 완료!");
}
public int size(){
return (top+1);
}
public boolean isEmpty() { return (this.top == -1); }
public boolean isFull() { return (this.top == this.capacity-1); }
}
| [자료구조] Java Tree 구현 / 자바 트리 구현 (0) | 2021.06.28 |
|---|---|
| [자료구조] Java Queue 구현 / 자바 큐 구현 (0) | 2021.02.04 |
| [Interface-초급] Java Interface란? / 자바 인터페이스란? (0) | 2021.01.16 |
| [클래스] Java Abstract Class / 자바 추상 클래스 (0) | 2020.12.31 |
| [자료구조] Java ArrayList 구현 / 자바 리스트 구현 (0) | 2020.12.27 |
ArrayList는 크기가 고정되지않은, 즉 동적 배열을 의미한다.
배열(Array)와의 차이점으로 배열은 초기화할 때 크기를 지정해야 하지만, ArrayList는 그러지 않아도 된다.
즉 배열은 고정값의 크기를 가지게 되고, 이후에 크기를 늘리는 행위를 하려면 새로운 배열을 생성하여 내용을 복사해야 하는 반면에, ArrayList는 그냥 추가해 주면 된다.
그렇다면 동적 크기를 갖는 ArrayList를 구현하려면 어떻게 해야할까?
다른 블로그 포스트들을 보면 똑같은 코드를 바탕으로 똑같은 설명을 반복하고 있다. 해당 내용을 보면 심화된 ArrayList를 구현할 수 있기 때문에 나는 기초 구현을 하겠다.
들어가기에 앞서서, 제네릭이라는 기술이 있다. 제네릭은 쉽게 말하면 하나의 구조에 대해 여러 자료형을 사용할 수 있도록 하는 것이다. 우리가 String name이라는 변수를 통해 홍길동, 김철수, 김영희 등을 지정하는 것 처럼 name을 String뿐만 아니라 Integer, Float, Boolean, 등 여러개의 자료형을 사용할 수 있도록 해주는 것이다.
이러한 제네릭을 사용하기 위해서는 제네릭 클래스를 만들어야하는데, 간혹 어떤 클래스를 볼 때 다음과 같은 구조를 본 적 있을 것이다.
class Point<T>{ ... }
여기서 <T>부분이 제네릭 부분이며, 내가 자료형을 T로 표현한 부분은 모두 해당 클래스를 사용할 때 지정한 자료형임을 나타내는것이다. 따라서 간략히 Point 내부에는 int x, y 혹은 Float x, y 대신 T x, y를 사용함으로써 Integer를 갖는 Point와 Float을 갖는 Point를 따로 만들지 않고 하나의 Point<T>를 통해 두가지를 모두 구현할 수 있게 되는 것이다.
Array List
이름을 보면 정답이 나온다.
Array List, 즉 Array를 이용하여 List를 만드는 것이다. Array는 고정 크기를 갖는데 어떻게 동적 크기를 만든다는거지?
본 게시글의 시작 부분에서 " ... 배열은 고정값의 크기를 가지게 되고, 이후에 크기를 늘리는 행위를 하려면 새로운 배열을 생성하여 내용을 복사 ... "
즉, ArrayList는 내부에 어떤 고정 크기를 갖는 배열을 가지고 있고, 어떤 요소를 추가할 때 그 배열의 크기를 넘어가게되면 배열의 크기를 늘려주면 된다.
ArrayList를 만들기에 앞서 목적이 무엇인지 생각해보자.
1. 어떠한 Data를 보관한다.
2. 보관된 Data를 반환한다.
1. Data를 보관할 때 조금 옵션을 추가해 보자면 제일 앞에, 제일 뒤에, 특정한 위치에 이렇게 3가지가 있을 수 있다. (제일 뒤는 가장 마지막으로 추가한 Data의 뒤를 의미)
2. Data를 반환할 때 마찬가지로 옵션을 추가해 보면 제일 앞에, 제일 뒤에, 특정한 위치에 이렇게 3가지가 있다.
위 목적을 바탕으로 ArrayList가 갖는 요소를 생각해 보면 Array, index(혹은 iterator)면 충분하다.
이제 ArrayList를 만들기 위한 준비는 끝났다.
Class ArrayList
class ArrayList{
Object[] arr = null;
int capacity = 0;
int size = 0;
ArrayList(int capacity){
this.capacity = capacity;
arr = new Object[capacity];
size = 0;
}
ArrayList(){
capacity = 1;
arr = new Object[capacity];
size = 0;
}
}시작은 위와 같다. ArrayList class에 대하여 array, arr의 크기를 알려주는 capacity, 그리고 현재 arr의 size를 반환해주는 size,를 만들었다. (size는 arr이 지금까지 사용하고 있는 크기, capacity는 arr의 length를 알려주는 변수이다.)
그리고 ArrayList를 생성함과 동시에 arr을 전달받은 size로 크기를 초기화하거나, 그렇지 않은 경우 배열의 크기를 1로 설정했다.(1 이상으로 해도 된다. 다만 0으로 할 경우, ArrayList 생성 후에 삽입을 한다면 에러가 발생하니 주의하자)
Data 보관
이제 데이터 보관을 구현할 차례다. 이 때 주의해야 할 점은 다음과 같다.
1. arr이 꽉찼다면, arr의 크기를 바꾸고 내용을 복사한다.
2. 삽입하는 위치가 특정 위치일 경우, 해당 위치부터 요소들을 뒤로 한칸씩 민다.
1번의 경우, 그림으로 표현하면 다음과 같다.

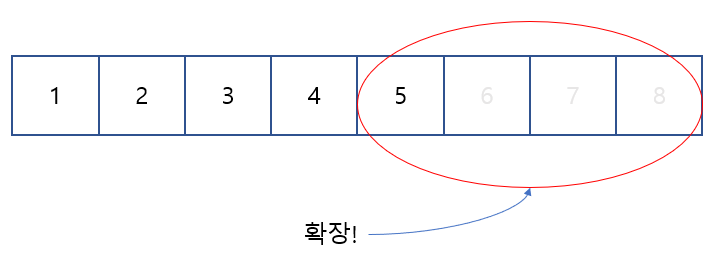
arr이 가득 찬 상태에서 새로운 요소를 추가한다면, 새로운 배열을 만들고, 해당 배열의 크기를 기존의 2배로 만들면 된다. 이후에 새로운 배열에 기존 배열을 복사 하고, 새로운 요소를 추가해주면 된다.
2번의 경우, 그림으로 표현하면 다음과 같다.
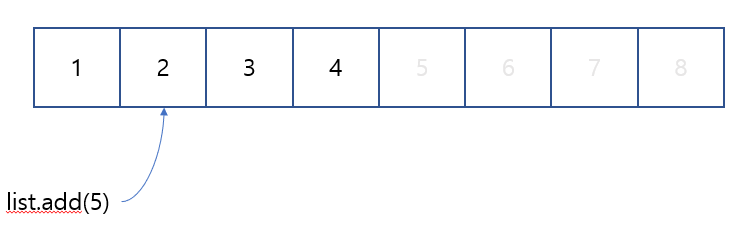

그림에서 보면 새로운 요소 5를 두번째에 추가하려고 한다.
하지만 이미 두번째부터 2, 3, 4라는 요소가 삽입되어 있다. 이럴 경우, 둘, 셋, 네 번째 위치의 요소들을 뒤로 한칸씩 밀어주고, 내가 원하는 위치에 데이터를 삽입하면 된다. 이를 응용하여, 제일 앞에 요소를 추가한다면, 모든 요소를 뒤로 한칸씩 밀어주면 된다.
이를 코드로 표현하면 다음과 같다.
class ArrayList{
...
public void add(Object element){
if(size == capacity){
expandArray();
}
arr[size++] = element;
}
public void addFirst(Object element){
add(0, element);
}
public void add(int index, Object element){
if(size == capacity){
expandArray();
}
for(int i = size; i >= index; i--)
arr[i] = arr[i-1];
arr[index] = element;
size++;
}
private void expandArray(){
capacity *= 2;
Object[] tempArr = new Object[capacity];
copyArr(tempArr, arr);
arr = new Object[capacity];
copyArr(arr, tempArr);
}
private void copyArr(Object[] arr1, Object[] arr2){
for(int i = 0; i < arr2.length; i++){
arr1[i] = arr2[i];
}
}
...
}요소를 추가할 때 마다 size는 증가하게되고 따라서 arr이 가득 차게 되면 size는 capacity와 값이 같아지게된다. 이를 조건으로 사용하여 arr이 가득 찼다면 expandArray함수를 호출함으로써 arr을 크기를 확장힌다.
기본적으로 add 함수는 배열의 가장 뒤에 요소를 추가하며, 추가하고자 하는 위치가 있을 경우 해당 index로 데이터를 삽입한다.
Data 반환
데이터를 반환하는 코드는 비교적 단순하다.
원하는 위치에 대해 Object를 반환해주면 끝이다.
class ArrayList{
...
public Object get(int index){
if(size <= 0){
System.out.println("배열이 비어있습니다.");
return null;
}
return arr[index];
}
...
}이 때 주의해야 할 점은 내가 구하고자 하는 위치가 배열의 크기를 넘어설 수 있다. 이를 따로 조건문으로 처리해주어도 되지만, 그냥 반환함으로써 Out Of Bounds 예외를 출력해주어도 되기 때문에 따로 작업하지 않았다.
추가적인 동작들
추가적으로 배열 초기화, 삭제, Size 반환, Capacity 반환 등이 있을 수 있다.
삭제의 경우, 삭제하고자 하는 위치가 배열의 크기를 넘어가는지, 이미 비어있는지 등을 확인하고 삭제, 반환해주면 된다. 나는 따로 조건을 추가하지 않았다.
초기화는 현재의 capacity로 arr를 초기화 시켜주면 된다.
class ArrayList{
...
public Object remove(int index){
/*
크기 초과, 이미 비어있는지 등 조건문은 원하는대로 추가해주면 된다.
*/
Object result = arr[index];
arr[index] = null;
return result;
}
public void reset(){
arr = new Object[capacity];
}
public int size(){
return this.size;
}
public int getCapacity() {
return this.capacity;
}
}전체 코드와 실행 결과
package DataStructure;
public class ArrayList<T> {
Object[] arr = null;
int capacity = 0;
int size = 0;
public ArrayList(int capacity){
this.capacity = capacity;
arr = new Object[capacity];
size = 0;
}
public ArrayList(){
capacity = 1;
arr = new Object[capacity];
size = 0;
}
public void add(T element){
if(size == capacity){
expandArray();
}
arr[size++] = element;
}
public void addFirst(T element){
add(0, element);
}
public void add(int index, T element){
if(size == capacity){
expandArray();
}
for(int i = size; i >= index; i--)
arr[i] = arr[i-1];
arr[index] = element;
size++;
}
private void expandArray(){
capacity *= 2;
Object[] tempArr = new Object[capacity];
copyArr(tempArr, arr);
arr = new Object[capacity];
copyArr(arr, tempArr);
}
private void copyArr(Object[] arr1, Object[] arr2){
for(int i = 0; i < arr2.length; i++){
arr1[i] = arr2[i];
}
}
public T get(int index){
if(size <= 0){
System.out.println("배열이 비어있습니다.");
return null;
}
return (T) arr[index];
}
public T remove(int index){
/*
크기 초과, 이미 비어있는지 등 조건문은 원하는대로 추가해주면 된다.
*/
T result = (T) arr[index];
arr[index] = null;
size--;
if(size > 0) {
/*
삭제한 이후부터 앞으로 한칸씩 땡긴다.
*/
for(int i = index; i < size; i++) {
arr[i] = arr[i+1];
}
}
return result;
}
public void reset(){
arr = new Object[capacity];
size = 0;
}
public int size() {
return this.size;
}
public int getCapacity() {
return this.capacity;
}
}package Main;
import DataStructure.ArrayList;
public class mainTask {
public static void main(String[] args) {
System.out.println("=====짧은머리 개발자=====");
ArrayList<Integer> arr = new ArrayList<Integer>();
System.out.println("배열 크기 : " + arr.getCapacity());
System.out.println("데이터 삽입 1~5");
for(int i = 0; i < 5; i++) {
arr.add((i+1));
}
//출력
System.out.println("\n==출력==");
for(int i = 0; i < arr.size(); i++) {
System.out.print(i + "번째 : " + arr.get(i) + " | ");
}
System.out.println("\n배열 크기 : " + arr.getCapacity());
arr.add(1, 6);
arr.add(4, 7);
System.out.println("\n==출력2==");
for(int i = 0; i < arr.size(); i++) {
System.out.print(i + "번째 : " + arr.get(i) + " | ");
}
System.out.println("\n배열 크기 : " + arr.getCapacity());
System.out.println("1번째 요소 삭제 : " + arr.remove(1));
System.out.println("\n==출력3==");
for(int i = 0; i < arr.size(); i++) {
System.out.print(i + "번째 : " + arr.get(i) + " | ");
}
System.out.println("\n배열 크기 : " + arr.getCapacity());
System.out.println("\n==출력4==");
while(arr.size() > 0) {
System.out.println("0번째 삭제: " + arr.remove(0));
}
System.out.println("\n배열 크기 : " + arr.getCapacity());
System.out.println("데이터 삽입 1~5");
for(int i = 0; i < 5; i++) {
arr.add((i*2));
}
//출력
System.out.println("\n==출력6==");
for(int i = 0; i < arr.size(); i++) {
System.out.print(i + "번째 : " + arr.get(i) + " | ");
}
System.out.println("\n배열 크기 : " + arr.getCapacity());
System.out.println("초기화");
arr.reset();
System.out.println("\n==출력7==");
for(int i = 0; i < arr.size(); i++) {
System.out.print(i + "번째 : " + arr.get(i) + " | ");
}
System.out.println("\n배열 크기 : " + arr.getCapacity());
}
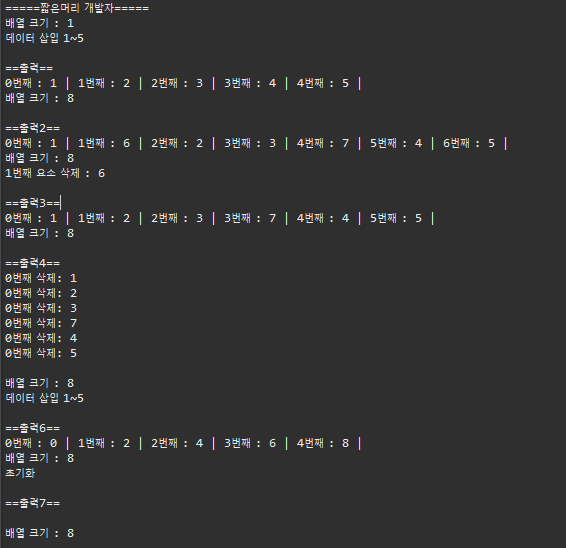
}
이상 ArrayList 게시를 마치고, 다음엔 Stack을 올려야겠다.
제네릭은 다음 글 부터 설명을 포함하여 쓰겠다. 일단 처음이니까 패스!
| [자료구조] Java Tree 구현 / 자바 트리 구현 (0) | 2021.06.28 |
|---|---|
| [자료구조] Java Queue 구현 / 자바 큐 구현 (0) | 2021.02.04 |
| [Interface-초급] Java Interface란? / 자바 인터페이스란? (0) | 2021.01.16 |
| [클래스] Java Abstract Class / 자바 추상 클래스 (0) | 2020.12.31 |
| [자료구조] Java Stack 구현 / 자바 스택 구현 (0) | 2020.12.29 |