오래전부터 태블릿에서 사용할 무선 마우스가 있으면 좋겠다는 생각을 했다. 그래서 태블릿에 사용할 무선 마우스를 찾고 있었는데, 내게 필요한 조건은 다음과 같았다.
1. 태블릿과 블루투스 페어링을 통해 연결이 되어야 할 것 2. 태블릿 이외의 다른 기기에도 연결이 가능해야 할 것 3. 오랜시간 사용해도 손에 무리가 적을 것 4. 적당한 가성비가 있어야 할 것
1번과 2번을 충족하는 제품은 많이 있었지만, 이와 동시에 3, 4번을 충족하는 제품은 없었다.
대표적으로 로지텍의 Anywhere, M720, 그리고 페블을 눈에 두고 있었지만 Anywhere은 너무 비쌌고, 로지텍 페블은 시기만 맞으면 1만원 중후반대에 제품을 구매할 수 있었지만 생김새 때문에 3번을 충족하지 못했다.
그래서 Anywhere와 페블의 중간에 형성중인 가격대, 3번을 충족하는 로지텍의 M720을 구매할 까 많이 생각했지만 4만원이라는 돈을 주고 사기에는 너무 아까웠다.
마우스 사는것을 위와 같은 이유로 미루고 미루다 어느날 페이스북의 광고에 내가 마우스 검색한 것을 인지했는지, 샤오미의 무선 마우스 광고가 나오는게 아닌가?
샤오미 하면 가성비, 그리고 이미지로 봤을 때 딱 느껴지는 오래 사용해도 손목에 무리가 적을 것 같은 생김새!
그래서 바로 구매를 했다. 12900원의 제품 가격과 배송비 2500원을 합해 15400원에 구매했으니, 페블보다도 저렴한 것이 아닌가!!
배송받은 제품은 다음과 같이 생겼다.
박스 전후면
제품을 구매할 때는 무소음 마우스인지 몰랐는데, 박스 전면에 Silent Edition이라 적혀있는 걸 보고 무소음 마우스라는걸 알았다.
후면에는 각종 설명이 중국어로 적혀있기 때문에, 눈길을 주지도 않았다.
개봉 하면 다음과 같이 생겼는데, 구성품은 정말 마우스 본체 하나, 제품 취급 설명서, 그리고 제품 사용 설명서 이렇게 3개가 들어있다. 건전지는 동봉되어 있지 않으니 따로 AAA 건전지 두 개를 준비해야 한다.
구성품
마우스의 전원을 위해 AAA 건전지 2개가 필요한데, 나는 여타 제품과 같이 AA 한개일 줄 알고 AA를 준비했는데,, 이로인해 AAA 건전지를 따로 구해야 했다. ㅠㅠ..
건전지 넣는법
건전지를 넣기 위해서는 마우스 바닥면에 있는 뚜껑(?)을 열어야 되는데, 위 사진처럼 시침 처럼 생긴 것을 왼쪽 파란 선까지 돌리면 열린다.
이후에 건전지를 넣어주면 된다. 건전지 사이에 보이는 동글이가 리시버다. 사용하고자 하는 데스크탑이나 노트북 등 USB를 꽂으면 연결된다.
본 제품은 기본적으로 블루투스 1대, USB 1대 총 2대의 연결만 지원하기에 비교대상이었던 로지텍의 타 제품은 3대 이상인걸 생각하면 아쉽긴 하지만, 12900원의 제품에서 그것 까지 바라는건 양심이 없는 것 같긴 하다.ㅋㅋㅋ
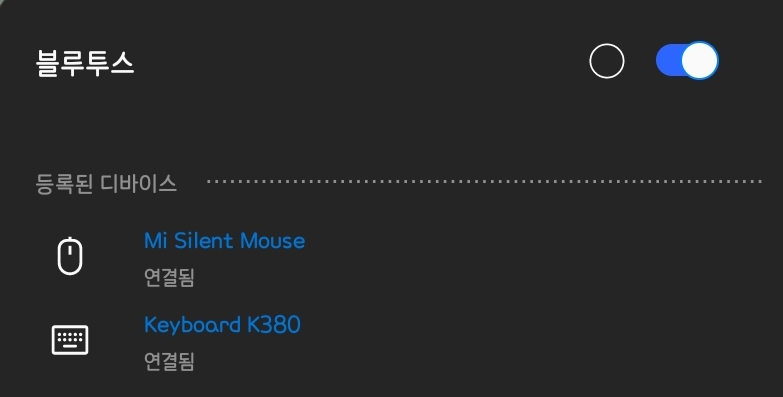
제품의 상단을 보면 마우스 휠 아래에 동그란 버튼이 있는데, 이 버튼이 바로 USB로 연결 할지, 블루투스로 연결할지 결정하는 버튼이다.
초록색은 USB 리시버, 파란색은 블루투스와 연결중이라는 의미다.
초록 불은 USB 리시버와 연결, 파란불은 무선 블루투스 연결을 의미한다.Mi Silent Mouse를 찾아 연결하면 된다.
블루투스로 연결하려 했는데, 만약 제품이 안뜬다면 마우스에 있는 동그란 버튼을 꾹 누르면 깜빡깜빡 거리며 페어링 모드로 진입하게 되고, 이 때 블루투스 검색란에서 Mi Silent Mouse를 찾을 수 있다. (새로운 기기에서 블루투스 페어링을 할 때도 이렇게 하면 된다.)
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
마우스 버튼을 눌러보면 왼쪽 클릭과 오른쪽 클릭 버튼은 정말 무소음에 가까운 걸 알 수 있다. 다만 좌측에 존재하는 페이지 앞/뒤 버튼은 무소음이 아니니, 독서실 등 조용한 곳에서 사용할 떄 주의해야 할 것 같다.
총평 (★★★★☆ - 4.5개임 사실)
12900원 짜리 마우스가 이렇게 높은 퀄리티를 보여줄 줄이야! 생김새도 무난하고, 사용성도 무난하고!
다만 별 한개를 깎은 이유는 데스크탑에서 DPI 설정이 안된다. 너무 빠르다. (사실 별점 4.5개를 주고싶은데 반쪽 짜리 별은 없어서..)
두 달정도 전 쯤에 키보드에 콜라를 쏟았던 적이 있다. 우측 Ctrl 키 부근에 쏟았는데, 작동도 잘 되고 딱히 불편함이 없어서 A/S를 보내지 않고 계속 쓰고 있었다.
음료를 쏟은지 한 달이 지나자 Ctrl 키를 눌러도 올라오지 않는 증상이 생겼다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
레오폴드 키는 특히 '한자' 키가 우측 Ctrl키와 함께 동작하는데, 내가 '한자'를 얼마나 자주 쓰는지 이 경험을 통해 알게 됐다.
불편함을 느끼게 되자 매우 신경쓰이고, 도저히 못쓰겠다 싶어서 레오폴드 공식 홈페이지에서 A/S를 신청하였고, 택배를 보낸지 2주쯤 지나자 수리된 제품을 받아볼 수 있게 됐다. (레오폴드는 우체국을 통해 택배를 보내니, A/S를 맡기고 연락이 없다면 우체국 앱을 통해 조회해 보자.)
레오폴드 A/S는 추가금이 발생할 때만 연락 온다고 알려져있는데, 이번주 월요일 레오폴드로부터 연락을 받아 속으로 많이 놀랐었다. (콜라 특성에 의해 기판이 부식되어 추가금이 발생하는건가..?ㅠㅠ)
전화를 받아보니, 내가 증상으로 첨부한 동영상의 기간이 만료되어 증상 확인이 불가능해 확인차 연락주신것 이었다.
A/S 언박싱!
레오폴드의 A/S는 키보드의 삼성급이라 알려져 있던 만큼 꽤 기대하고 있었다. (다른 분들의 후기를 보면 보낸지 3일만에 받은 사람도 있어서 시간적으로도 금방 될거라 기대했지만..ㅠㅠ 2주가 걸렸다. 기간은 레오폴드 공식 홈페이지에 매번 공지되니 잘 확인하면 좋을것 같다.)
뽁뽁이는 가지런하게 잘 싸여 왔고, 뽁뽁이를 뜯은 박스의 상태가 꽤 깨끗해서 새 박스인가? 하는 착각이 들 정도였다.
박스를 열면 키보드 위에 뽁뽁이를 올려주신 후기도 봐서 나도 그러면 좋겠다는 생각을 했지만, 나는 그냥 키보드만 왔다. ㅠㅠ (그런데 박스 내부가 보낼 때 닦아서 보냈는데 먼지가 많이 쌓여서 왔다. 2주간의 기다림 때문인가..?)
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
키보드는 정상적으로 동작하는 것을 모두 확인했다. 무엇보다 전보다 키들이 더 부드러워 진 것 같은 착각도 든다.
키보드 수리기간 동안 블루투스 키보드를 사용하면서 손목이 꽤 많이 아팠는데, 이제 안아파도 된다는 생각에 너무 좋다.
중앙화 블록체인을 만들면서 Transaction을 효율적으로 검색할 수 있는 시스템을 개발하던 중, ElasticSearch라는 기술을 알게됐다. 기존에는 파일 형태로 Transaction을 저장하려 했으나, 이후 주어진 Transaction을 검증하는데 있어 오랜 시간이 소모될 것 같아 해결법을 강구하던 중 알게된 기술이다. ElasticSearch는 기본적으로 REST API 통신으로 데이터를 조작할 수 있었고, 여기에 Transaction 저장방식을 객체형 DB인 MongoDB에 저장하기로 했다.
File로 저장할 때에도 JSON 타입으로 저장하여 ElasticSearch를 연계할 수 있었지만, 그냥 파일로 저장 안하고 MongoDB에 저장하기로 결정했다. (MongoDB에만 Transaction을 저장하는건 문제가 될 수 있지만, 개발하고 있는 블록체인에서는 Authenticator라는 역할이 몇명 존재하기 때문에, 여기에 약간의 분산저장을 하고 있어서 크게 신경쓰지 않기로 했다.)
Linux와 관련된 글은 많았으나, 이번에 개발하는 서버가 Windows 기반이기에 관련 자료가 거의 없다싶이 하여 글을 쓰게 됐다.
구현하고자 하는 기능은 다음과 같다. MongoDB에 어떤 데이터가 저장되면 ElasticSearch의 데이터로 동기화시켜 데이터를 구할때는 MongoDB가 아닌 Elastic Search에서 가져올 것이다.
사용된 MongoDB와 ElasticSearch 그리고 Logstash의 버전은 다음과 같다.
Logstash를 설치한 이후에, mongodb input 플러그인을 설치해줘야 하는데, 정말 쉽게 cmd로 설치할 수 있었다. (관련된 글들이 모두 linux 기반이고, 명령어 또한 linux의 그것과 닮았기에 윈도우에서 동작 안할 줄 알았는데, 된다. 이걸로 이틀은 날려먹은 것 같다.)
cmd 명령 프롬프트 창을 관리자 권한으로 실행시킨 뒤, 다음 명령어를 입력하면 logstash-input-mongodb가 설치된다.
cd \path\to\logstash\bin\logstash-plugin install logstash-input-mongodb
만약 Success to installation( 정확히 기억 나지는 않지만 )과 같이 설치에 성공했다는 문구가 안뜨면, 오류가 함께 출력되니 그에 맞춰서 대응하면 된다.
이후 logstash를 이용하여 mongodb로부터 데이터를 가져와 elasticsearch로 넘겨주는 설정이 필요하다. 해당 설정은 다음과 같다.
# Sample Logstash configuration for receiving # UDP syslog messages over port 514 input { mongodb { uri => '몽고DB 주소' placeholder_db_dir => '입력 저장할 파일 경로' placeholder_db_name => '저장할 파일 이름' collection => '가져올 collection 이르' batch_size => 2000 generateId => false parse_method => "simple" } } filter { mutate { copy => { "_id" => "[@metadata][_id]"} remove_field => ["_id"] } } output { elasticsearch { hosts => ["엘라스틱 서치 주소"] index => "데이터를 삽입할 index 명" document_id => "%{[@metadata][_id]}" } stdout { } }
batch_size: 한번에 가져올 수 있는 최대 양 이다. placeholder_db_dir에 저장된 placeholder_db_name을 지운다고 해서 Elastic Search에 동기화된 내용이 삭제되는 것은 아니다. 따라서 데이터의 삭제를 위해서는 elastic search에서 직접 제거해주어야 한다.
filter같은 경우에 엘라스틱 서치의 _id와 몽고db의 _id가 겹쳐서 오류가 발생할 수 있기 때문에, 몽고db의 _id를 나는 제거해주었다.
파일 명은 mongodb.conf 이며, 저장 위치는 logstash가 설치된 폴더의 config 폴더 내에 저장했다. ( \logstash\config\mongodb.conf\ )
이후 logstash를 실행 시켰을 때 정상적으로 실행된다면 성공이다.
사실 몽고DB와 엘라스틱 서치는 따로 건드리는 것 없이 logstash만 잘 설정해주면 작동해야만 한다. 몽고DB와 엘라스틱 서치가 정상적으로 동작하지만, sync가 안된다면 logstash의 설정에서 무엇인가 잘못된 것이니 logstash에서 찍히는 log를 잘 읽어보면 해결할 수 있을것이다.
프로그래밍에서 의존성이라고 하면, 예를 들어 A라는 객체를 만들 때 A의 원형태라고 생각하면 쉽다. 즉, A 객체는 A 클래스에 의존하여 생성되는 것이다.
Car myCar = new Hyndai();
위 코드에서는 myCar가 Hyndai에 의존한다는 것을 알 수 있다.
프로그램을 만들고, 이후에 코드를 업데이트 해야하는 경우가 발생하면, A와 연관된 클래스를 모두 수정해야 하는 일이 발생한다. 즉 의존성을 일일이 모두 변경해줘야 하는 것이다.
만약 내가 현대차에서 Kia차로 바꾼다면 어떻게 해야할 까? myCar가 사용되는 모든 곳에 대해 Hyundai를 Kia로 바꿔줘야 하는 상황이 발생하는 것이다.
Car myCar = new Kia();
Car myCar = new Hyundai();
...
class Hyundai extends Car{
...
}
class Car implements Vehicle{
...
}
interface Vehicle{
...
}
기존에는 위와 같이 코드를 작성한다 할 때, myCar를 만드는 순서는 다음과 같다.
Hyundai -> Car -> Vehicle
Class Diagram으로 설명하면, 위 코드는 다음과 같은 그림을 갖는다.
즉 myCar를 만들기 위해 Hyundai를 만들고, Hyundai를 만들기 위해 Car, Car를 위해 Vehicle이 만들어 지는 것이다.
위처럼 Car myCar = new Hyundai()처럼 직접 객체를 만들고 의존하는 방식을 Composition has a 라고 하는데, 우리는 연결형, 즉 Association has a를 만들려고 한다.
Composition has a는 위에서 언급 했듯이, Kia차로 차를 바꾼다면 모든 myCar를 Kia로 바꿔줘야 하기 때문이다.
Association has a를 한 코드로 예를 들면, 다음과 같다.
...
class Car{
Car car;
...
void setCar(Car car){
this.myCar = car;
}
}
...
Hyundai hyundai = new Hyundai();
Car myCar;
myCar.setCar(hyundai);
...
Car를 연결하는 Hyundai를 따로 만들고, 이를 setter 등을 이용하여 myCar의 Car에 연결하는 것이다. 이렇게 되면 myCar를 바꿀 필요 없이 Hyundai의 선언만 Kia로 바꿔주면 된다.
하지만 스프링은 이를 xml 등을 이용하여 소스를 직접 수정하지않고, 구성 파일만 수정함으로써 의존성을 변경할 수 있게 해준다.
이를 의존성을 주입한다고 하는데, 영어로는 Dependency Injection다.
Inversion of Control ?
갑자기 Inversion of Control이 나와서 이게 뭘까 싶을 수 있다. IoC는 자바의 DI를 이해하기 위해서 알아야 하는 속성인데, 구글 번역기를 돌려보면 "제어 반전"이라는 해석이 나온다. 제어??? 반전??? 도대체 무슨말이야??
위에 Class Diagram으로 Composition has a의 순서와 반대로 생성되는 것이다.
Vehicle -> Car -> Hyundai
이 순서로 생성되는 것인데, 이는 이미 스프링의 어떤 xml 파일에서 beans로 정의되어 있기 때문에 가능한 것이다.
xml에 정의되어있는 어떤 컨트롤을 내 소스에 주입 하는 것인데, 쉽게 말하면 만들어진 Hyundai, Kia를 내 myCar.setCar(hyundai) 혹은 myCar.setCar(kia)와 같은 방식으로 자동으로 설정되게 하는 것이다.
이를 이용하면 소스파일의 수정 없이 의존성을 주입할 수 있다.
직접 주입해보자!
이러한 스프링 xml파일을 만들기 위해서는 springframework의 spring-context를 이용하여야 한다. 이를 pom.xml에 넣어주자. 이는 maven을 이용한다면, maven에서 dependency를 추가해주면되고, 그렇지 않다면 직접 코드를 추가해주면 된다. 나의 경우 maven repository에서 추가했고, 추가된 코드는 다음과 같다.
이후에 src폴더에 xml만 모아놓은 폴더여도 좋고, DI를 이용하는 소스가 있는 폴더에 넣어도 좋다. 개인적으로는 DI xml을 넣는 폴더를 따로 만들어 관리하기를 추천한다.
이클립스에서 새로 추가하기 -> Other -> Spring -> Spring Bean Configuration File을 추가해 주고 이름을 적절히 설정하면 name.xml파일이 생성된다.
나는 myCar.xml이라 하겠다.
우선, Car 클래스와 관련된 소스는 아래와 같다.
public interface Vehicle {
int getWheels();
String getNames();
}
public class Car implements Vehicle {
String name;
int wheels;
public Car(String name, int wheels) {
this.name = name;
this.wheels = wheels;
}
@Override
public int getWheels() { return wheels; }
@Override
public String getNames() { return this.name; }
public void setWheels(int wheels) { this.wheels = wheels; }
public void setName(String name) { this.name = name; }
@Override
public String toString() {
return "Car [name=" + name + ", wheels=" + wheels + "]";
}
}
public class Hyundai implements CarUI {
private Car car;
public Hyundai() {
}
@Override
public void print() {
System.out.println("*************");
System.out.println("HYUNDAI " + car.toString());
System.out.println("*************");
}
public void setCar(Car car) {
this.car = car;
}
}
public class Kia implements CarUI {
private Car car;
public Kia() {
}
@Override
public void print() {
System.out.println("=============");
System.out.println("KIA " + car.toString());
System.out.println("=============");
}
public void setCar(Car car) {
this.car = car;
}
}
public interface CarUI {
void print();
}
Spring을 사용하지 않을때 myCar를 설정한다면, 다음과 같이 해야 했다.
public class MyOwnCar {
public static void main(String[] args) {
Car hyundai = new Car("SUV", 4);
Hyundai myCar = new Hyundai();
myCar.setCar(hyundai);
myCar.print();
}
}
즉, 내 차가 Kia차로 바뀐다면, 아래와 같이 바뀌어야 했다.
public class MyOwnCar {
public static void main(String[] args) {
/*
Car hyundai = new Car("SUV", 4);
Hyundai myCar = new Hyundai();
*/
Car kia = new Car("SUV", 4);
Kia myCar = new Kia();
myCar.setCar(kia);
myCar.print();
}
}
이제는 myCar.xml을 통해 이러한 행동을 하지 않으려고 한다.
스프링에서는 xml과 같은 DI 지시서를 이용하기 위해서는 Spring context를 이용하여야 하는데, 코드로 다음과 같이 작성한다.
ApplicationContext context = new ClassPathXmlApplicationContext("spring/di/myCar.xml");
ApplicationContext를 xml로부터 가져오는데, "spring/di/myCar.xml"이 내가 불러오고자 하는 DI 지시서의 경로인 것이다.
이후 context.getBean을 통해 해당 DI 지시서에 등록되어있는 beans를 이용할 수 있다.
bean을 이용하는 방법은 다음과 같다.
<bean id="의존성 주입할 객체의 변수명" class="해당 객체의 형태를 나타내는 class경로" />
즉, 내 myCar의 경우에는
<bean id="myCar" class="spring.di.entity.Car" />
이 된다.
만약 의존성을 주입할 때 그냥 설정만 하는거라면 우리가 일일이 변수를 다 변경해줘야 하고, 그렇다면 스프링은 지금처럼 많이 쓰이지 않았을 것이다. 한마디로 스프링은 변수와 같은 속성 설정도 지원하는데, 다음과 같은 속성을 사용할 수 있다.
1. index : n번째 index를 설정한다. 2. name : name과 동일한 이름을 갖는 변수를 설정한다. 3. p : p:"NAME" 에서 "NAME"과 동일한 변수를 설정한다. 이 때, xmlns:p="http://www.springframework.org/schema/p" 를 추가하여야 한다. 4. setter를 직접 사용한다.
각각 사용하는 방법은 다음과 같다.
<bean id="myCar" class="spring.di.entity.Car">
<!-- 1번. index를 이용하는 경우 -->
<constructor-arg index="0" value="SUV" />
<constructor-arg index="1" value="4" />
<!--
만약 생성자가 2개 이상이고, 자료형만 다른 parameter를 전달 받는다면 type을 이용해 구분할 수 있다.
<constructor-arg index="0" type="int" value="4" />
<constructor-arg index="0" type="String" value="SUV" />
-->
<!-- 2번 name을 이용하는 경우 -->
<property name="name" value="SUV" />
<property name="wheels" value="4" />
<!-- 3번 p 속성을 이용하는 경우 -->
<bean id="myCar" class="spring.di.entity.Car" p:name="SUV" p:wheels="4" />
<!-- 4번. 직접 setter를 이용하는 경우 -->
myCar.setName("SUV");
</bean>
나머지 경우는 모두 직접 해보시길 바라고, 나는 2번 name을 이용하였을 때의 결과를 보여주겠다.
JSP 혹은 서블릿을 이용해 웹 서버를 개발할 때 파일 입출력 관련 프로그래밍을 해야하는 경우가 있다. 이 때, 출력 파일의 권한을 수정할 때, 수정되지 않는 경우가 있다. 이번 게시글에 작성할 문제의 경우, 파일을 생성할 때는 정상적으로 권한이 변경됐으나, 폴더를 생성할 때는 권한이 정상적으로 변경되지 않았다. 아무리 생각해봐도 톰캣의 권한 문제라면 생성되는 파일또한 권한이 정상적으로 변경되지 않아야 했으나, 정상적으로 출력되는 바람에 꽤 많이 헤매었다.
2021.11.23 추가
만약에, 아래 문단의 방법으로 안될 경우 아래 명령어를 통해 ReadWritePaths가 정상적으로 수정되었는지 확인해보자. 아직까지 왜 파일이 설정한대로 안바뀌는지 이유는 찾지 못했다. 이유를 찾으면 게시글을 업데이트 하겠당.
$ systemctl edit --full tomcat#.service
...
ReadWritePaths=대상폴더 ...
이 명령어를 통해 어떤 폴더에 권한을 줄 경우, 해당 폴더는미리 생성되어 있어야 한다. 뿐만 아니라, 아래 방식의 tomcat9.service에도 똑같은 내용을 적어놓는 것을 추천한다.
Tomcat 버전 9 이상의 경우, 톰캣이 실행할 웹앱 디렉토리의 소유자에 대하여 tomcat 계정, 혹은 tomcat이 추가된 그룹으로 바꾸고, 아래 루트로 이동하여 ReadWritePaths에 해당 웹앱의 ROOT 디렉토리를 추가한다.
인터페이스를 한 단어로 표현하면 '규약'이다. 개발하면서 꼭 지켜야 할 '규약'같은 존재로, 바꿔말하면 개발할 때 반드시 포함해야하는 멤버를 모아놓은것이 인터페이스다. 이렇게 말하면, 추상 클래스와 다른점이 무엇인지 헷갈릴 수 있다. 추상 클래스는 쉽게 말해 개발이 들어간 시점에서 공통된 속성을 모아놓은 클래스이며, 해당 추상 클래스를 '상속'하는 클래스는 해당 추상 메소드들을 모두 구현하여야 한다. 인터페이스는 이와 다르게 개발이 들어가기 전에 만들어질 메소드들에 대해 '규칙'을 정해놓은 것이고, 이를 '구현'하는 클래스들은 해당 메소드들을 모두 내용을 담아 만들어야 한다.
규칙? 그게 뭔데?
아직까지 이해가 안되는가? 그렇다면 경우를 들어 설명해 보자면, A와 B가 함께 자동차 객체를 생성하는 클래스를 만든다고 하자. 이 때, A는 자동차의 구동을 담당하고, B는 자동차의 프레임을 담당한다고 하자. 결국 자동차는 프레임과 구동부가 결합되어야 하는데, 만약 결합부가 일치하지 않는다면 설계에 실패했다고 볼 수 있고, 즉 자동차 객체를 생성 못한다고 볼 수 있다. 이를 위해 결합부에 대해 어떻게 설계하겠다는 약속을 정해야 하는데, 이를 인터페이스를 이용해 약속하는 것이다.
인터페이스 생김새
인터페이스는 이렇게 생겼다.
interface CarInterface{
public void move();
public void setSpeed(int speed);
}
CarInterface는 move와 setSpeed에 대해 설계 방식을 정하고 있고, 해당 인터페이스를 구현하는 클래스들은 두 함수에 대해 실질적인 내용을 담아야한다. 즉, 인터페이스는 함수내부가 어떻게 생겼을 지 모르겠지만, return 타입, 받아들일 파라미터 등 함수가 어떻게 생겼는지를 정해놓은 것이다. 따라서 A와 B가 같은 자동차를 설계하기 전에 인터페이스를 만들어 놓고, 결합부에 대해 약속을 정한다면 결합부가 일치하지 않아 자동차를 만들 수 없는 일은 발생하지 않을것이다.
왜 하필 인터페이스? 추상 클래스로는 안돼?
인터페이스가 가지는 추상클래스와의 가장 큰 다른점은 재사용성이다. 클래스는 다중상속이 불가능하지만, 인터페이스는 다중상속이 가능하다.
interface Vehicle{
public void move();
}
interface WheelObjects{
public void setWheels();
public void getWheels();
}
interface Car extends Vehicle, WheelObjects{
public void setHorsePower(float horsePower);
}
interface Airplane extends Vehicle{
public void setMaha(float Maha);
}
위와 같은 다중상속이 가능해짐으로써, Car라는 인터페이스를 만들기 위해 Vehicle과 WheelObjects의 인터페이스를 상속받아 각 인터페이스가 갖는 규칙을 모두 가질 수 있는 것이다. 뿐만 아니라, Vehicle 인터페이스를 Car에만 사용하는 것이 아니라 Airplane이라는 움직이는 방법이 전혀 다른 이동수단이 상속받을 수 있게 설계할 수 있다. 만약 추상클래스였다면, Car가 갖는 속성들을 Airplane은 가질수 없는게 당연한것과는 반대되는 성질이다. Java 8이 넘어가면서 추상클래스와 인터페이스의 관계는 많이 모호해지긴 했지만, 인터페이스의 특징을 잘 살리면 인터페이스 나름의 이용성이 큰 녀석이기 때문에 잘 이해해두면 좋은 친구다.