그러려면, 우선 블록이 어떻게 이루어지는지 알아야 한다. [1. 블록체인이란?]에서 언급한 바와 같이 블록은 Transactions, timestamp, nonce, ..., previous_blocks_hash_id를 사용하여 블록의 hash ID가 결정된다.
지금 검증하고자 하는 것은 블록의 실질적인 내용이고, 등록하고자 한 데이터의 한 형상인 Transactions이다.
Transaction
Transaction은 거래라는 의미를 갖고 있다. 비트코인으로 예를 들면, "A가 B에게 10만큼의 비트코인을 전송했다."를 Transaction이라 생각하면 된다.
이후에 아무 B는 비트코인을 사용하거나 전송하지 않았으면, B는 적어도 10만큼의 비트코인을 갖고 있어야 한다.
따라서 B는 자신이 비트코인 10만큼을 소유하고 있다는 것을 남들에게 알리려면, 적어도 해당 Transaction이 유효하다는 것을 검증해야 한다.
Merkle Tree
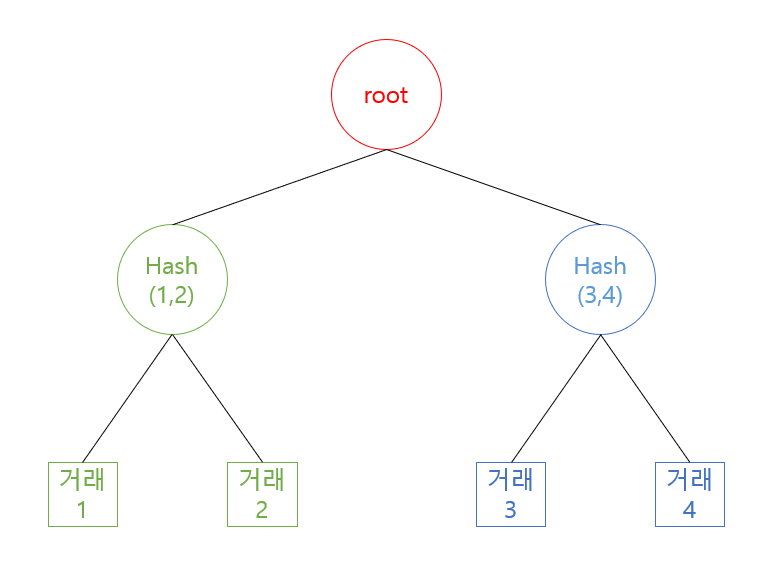
이제 블록에 등록되는 내용 중 새로운 친구인 Merkle Tree에 대해 설명하고자 한다.
Merkle Tree는 Hash Tree라고도 불린다. 따라서 어떤 해시 된 데이터들을 node로써 갖고 있는 Tree다.
우선, 위에서 든 예로 "A가 B에게 10만큼의 비트코인을 전송했다." 라는 데이터가 있다고 하자. 하지만, 실제로 우리는 Transaction을 봤을 때, A와 B를 지목하거나 대상을 구체화 할 수 없다. 그 이유는 데이터가 해시 되어서 블록에 저장되어 있기 때문이다.
즉, 거래 내역에 대한 데이터가 해시 되어 Transaction으로 존재하게 된다. 대충 Merkle Tree에 어떤 정보들이 존재하는지 짐작이 가지 않는가?
Merkle Tree는 Binary Tree로 생각하면 구현하기 쉽다. 그 이유는 다음 글을 참고하길 바란다.
Transaction을 두 개씩 짝지어 하나의 해시 값을 만들고, Bottom Up 방식으로 node를 만들어 나가다보면, 언젠가 트리가 완성될 것이다. 이 때, 트리의 root 값이 나오게 되는데, 이 값이 중요하다.
검증!
이제 검증이 어떻게 이루어지는지 설명할 차례다.
이쯤되면 우리는 각각의 character(마땅히 단어가 생각나지 않는다.) 혹은 character의 집합을 hash 했을 때 고유한 값이 나오는 것을 알고 있다.
즉, 거래의 내용이 변하면 hash값도 변하게 되고, 이를 이용해 Merkle Tree를 만들었을 때 다른 Root값이 나올것이다.
따라서 내가 검증하고자 하는 어떤 데이터가 블록체인에 정상적으로 등록되어 있다면, Merkle Tree를 다시 만들었을 때, Root Node의 값은 블록을 생성할 때 나왔던 값과 같을 것이고, 이로써 내가 갖고있는 데이터가 유효함이 검증된다.
*Merkle Tree에 쓰인 다른 Transaction은 다른 네트워크 참여자에게 요청하여 얻을 수 있다.
정리하면
내가 검증하고자 하는 데이터를 해시하여 Transaction을 만들고, 해당 Transaction을 바탕으로 블록의 Merkle Tree를 재구성하여 Tree의 Root 노드가 같은 값을 갖고 있다면, 데이터는 유효하다. 다른 값이 나오면, 해당 데이터는 유효하지 않은 것이다.
사실 여기까지의 내용으로 간단한 중앙화 블록체인(Centralized Blockchain Network)을 구현할 수 있다.
블록체인은 탈중앙화로 알고있는 사람들이 많기 때문에, 다음 글에서는 중앙화 / 탈중앙화 그리고 공개 / 비공개 블록체인 네트워크에 대해 글을 써야겠다.
오늘은 작업증명에 대해 알아보려 한다. 블록체인에서 작업증명은 빼놓을 수 없는 중요한 내용이다.
앞 글의 제일 하단에 보면, 블록체인의 해킹이 왜 어려운지 합의 파트에서 설명하겠다고 작성하였고, 이 문장을 보면 블록체인에서 어떤 합의를 해야 하기 때문에 해킹이 어렵다고 으레 짐작할 수 있다.
비트코인에서 합의 알고리즘은 작업증명(Proof of Work)를 채택하고 있다.
합의
그렇다면 합의는 무엇일까?
합의는 간단하게, 블록체인에 등록될 어떤 거래 내역(Transactions)들에 대하여 정상적(valid)이라고 많은 사람들이 동의하는 것이다.
모두가 4994가 값이라고 알려주고 있고, 따라서 이는 유효하다.
비트코인에서는 작업증명을 통해 Nonce를 찾고, 해당 값이 Maximum Value보다 낮으면 합의하게 되고, 이 Nonce를 찾은사람에게 비트코인을 보상으로 제공한다. 이 때, 해당 Nonce와 블록 내용으로 누가 되었건 hash를 했을 때, 같은 값이 나오고 해당 난이도 시점에서 valid한 값을 찾기 때문에, 모두가 동의할 수 밖에 없는것이다.
특정 참가자들이 771을 주고있지만 이는 채택되지 않는다.
실제 합의 알고리즘은 작업증명, 지분증명, 위임지분증명, ... 등 많은 종류가 있고, 해당 내용은 나중에 중요한것만 다루도록 하겠다.
해킹이 어려운 이유?
블록체인이 해킹이 어려운 이유는 보통 다음과 같다.
1. 이미 생성된 블록들의 내용을 변조하는 것은 불가능하다. 2. 전체 블록체인의 참여자의 50%가 해당 블록에 대해 동의해야 한다.
1번은 앞 글에서 설명한 것 처럼, N번째 블록은 해시 ID를 생성할 때, (N-1)번째 블록의 해시 ID를 사용하기 때문에, 이미 생성된 블록의 내용을 변조하는 것은 해당 M번째(변조된 N) 블록의 해시 ID가 변하게 된다. 이는 기존 (N+1)번째 해시와 (M+1)번째 해시가 달라지게 되고 결국 사슬이 끊어지는것을 의미하며, 해당 블록들은 무의미한 블록이 된다.
2번은, 기본적으로 블록체인은 Peer to Peer 네트워크로 이루어져 있다. 참여자들이 노드 정보(Block정보)를 갖고 있게 되고, 따라서 블록의 내용을 다른 참여자와 비교 하였을 때, 절반 이상 같은 내용을 가지고 있어야만 해당 노드가 유효하게 된다. 앞 1번의 이유로 인해, 이미 생성된 블록을 해킹하는건 불가능하고, 즉 새로 생성될 블록에 내가 변조 내용을 넣어야 한다. 그러나 블록체인 네트워크는 "나"만을 가리켜 블록에 대한 합의를 해달라고 요청하지 않고, 네트워크의 모든 참여자에게 합의를 요청한다. 이는 결국 해당 블록에 대한 합의는 작업증명을 기준으로 모두 같은 값을 줄 것이고, 중간에 변조내용을 심은 사람만 다른 값을 줄 것이다. 이 때 블록체인은 어떤것이 유효한지 선택하여야 하고, 결국 많은 사람들이 동의한 내용을 채택할 것이다.
이를 다시 말하면, 내가 전체 블록체인 네트워크의 51%에 대한 힘을 가지고 있어야만 블록체인에 해킹된 내용을 심을수 있다는 것과도 같다. 이제 왜 블록체인 해킹이 어려운지 이해가지 않는가?
정리하면
블록체인 네트워크는 합의를 통해 새로운 블록을 생성하고, 해킹을 시도한다면 변조된 내용을 동의할 만큼 센 힘을 가지고 있어야 한다.
다음 글에서는 내가 갖고있는 거래 내역이 어떻게 블록체인에서 검증되는지, 어떻게 유효성이 유지되는지 설명하는 글을 올리겠다.
나는 블록체인을 쉽게 얘기할 때, '일종의 데이터 저장 시스템' 혹은 '일종의 데이터베이스와 같은 것'이라고 얘기한다.
그렇다면 블록체인은 데이터 저장 시스템인데 왜 사람들이 어렵다 말하고, 비트코인이 유명해진걸까? 본 글에서는 사토시 나카모토의 비트코인을 기반으로 블록체인을 설명하려고 한다.
비트코인
우선 비트코인이 무엇인지 알아볼 필요가 있다. 사실 지금 가상화폐로 인해 비트코인이 무엇인지 모르는 사람은 없겠지만, 우리는 블록체인으로서 비트코인이 어떻게 동작하는지 알 필요가 있다.
Bitcoin: A Peer-to-Peer Electronic Cash System, Satoshi Nakamoto, 2008.
놀랍게도 비트코인은 2008년에 논문이 공개되었고, 2009년에 발행이 시작된 가상화폐다. 2009년부터 비트코인을 구매하기 시작했다면, 지금 엄청난 부자가 되었겠지?
블록체인 기술이 주목받기 시작한 이유는 하드웨어의 발전을 빼놓고 얘기할 수 없다. 왜 하드웨어가 중요한지, 도대체 블록체인이 뭔지 이제 시작해보도록 하자.
블록체인, 말 그대로 블록을 연결한 구조
<간단한 블록체인>
블록-체인. 즉 블록을 사슬처럼 연결하였다는 뜻이다. 사슬을 이루는 각각의 블록은 거래 내역(지금부터 데이터라 칭하겠다.)을 가지고 있고, 이러한 블록들이 연결되어 있다. 단순히 연결되어 있다면, 사슬이라는 이름보다는 블록-리스트 라는 이름이 되었을 것이다.
따라서 '사슬'처럼 쉽게 끊어낼 수 없는 어떠한 알고리즘이 사용되어야 하고, 비트코인에서는 Hash(암호화)를 이용하였다. 단순히 현재의 블록이 갖고 있는 내용만으로 Hash를 하였다면, 마찬가지로 단순한 '리스트'였을 것이다. 이를 해결하기 위해 각각의 N번째 블록은 자신의 ID를 만들기 위해 그 앞번째, (N-1)번째의 블록 정보를 이용하여야 한다.
<ID Hash>
만약 여기까지 이해했다면, 다음과 같은 의문이 생길수 있다. "그러면 블록의 정보들만 모두 구할 수 있으면 똑같은 블록을 만들 수 있는거 아니야? 내가 알기로 블록체인은 변조가 어려운 걸로 알고 있는데"
맞는 말이다. 블록의 내용만으로 똑같은 블록을 구성할 수 있고, 블록체인을 이룰 수 있다면, 비트코인의 가격이 폭등하지도 않았고, 그래픽카드 대란이 일지도 않았을 것이다.
즉 블록의 ID를 만들기 위해서는 추가적인 기술이 필요하고, 흔히 난이도라고 부르는 것이 그것이다.
*Hash : 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수, 나무위키, 비트코인에서는 SHA-256을 이용하였다.
난이도
난이도가 꽤 어려운 내용이기 때문에, 여기서는 단순하게 난이도가 어떤것인지 설명만 하도록 하겠다.
난이도라는 이름 그대로, 쉽게 말하면 블록을 생성할 때의 난이도다. 난이도가 쉽다면 블록을 누구나 만들 수 있을것이고, 난이도가 어렵다면 블록을 아무나 쉽게 만들지 못할 것이다.
비트코인은 SHA-256을 이용하여 데이터를 해시하였으며, SHA 함수는 값마다 서로 다른 해쉬값을 뱉어내는데, 예로 다음과 같다.
조금만 값이 바뀌어도, 전혀 다른 결과가 나오는 것을 볼 수 있다. 이에 착안하여, 비트코인에서는 Nonce라고 불리는 값을 내가 만들고자 하는 블록의 데이터에 추가한다. 위의 그림 <ID Hash>를 보면, Transactions + Timestamp + Nonce + ... + Prev_ID라 이해하면 된다.
위의 해시 결과를 보면 알겠지만, 대소문자만 바뀌어도 값이 변하기 때문에, Nonce는 막 수학적으로 계산하거나, 어려운 값을 넣을 필요 없이 단순히 숫자 0부터 조건을 만족할 때 까지 1씩 증가시키면 된다.
비트코인에서는 그 조건으로, 해시된 결과의 앞 n개의 글자가 0이면 된다. 최초에는 000000... 으로, 0이 6개 나오면 됐지만, 하드웨어가 발전함에 따라 해시속도는 급격하게 빨라졌고, 따라서 지금은 가변적인 난이도를 갖게 되기 때문에 n개의 글자수가 0이면 되는 것이다.
000000을 만드는것도 쉬운거아니야? 라고 생각할 수 있는데, i5-9600KF 기준으로 000000을 찾는데 평균 2분 30초 정도 걸리며, i9 10900으로는 1분 30초가 소요된다.
이러한 난이도(Nonce)를 찾는 행위를 작업증명이라고 한다.
정리하면
블록체인은 앞 블록의 Hash값과 현재 만들고자 하는 블록의 정보(Transactions, Timestamp, ...)를 함께 Hash하여 원하는 조건이 되는 ID를 가지는 블록들로 이루어진 데이터 사슬이라고 보면 된다.
"그러면 해킹은 왜 어려운거야?" 라는 질문이 생길수도 있는데, 이는 아직까지 설명하기엔 쉽지 않다. 하지만, 사람들이 흔히 말하는 내용처럼, "비트코인 네트워크의 절반 이상이 해킹된 내용을 갖고 있어야해."가 그 정답이다. 이는 나중에 합의파트에서 설명하도록 하겠다.
중앙화 블록체인을 만들면서 Transaction을 효율적으로 검색할 수 있는 시스템을 개발하던 중, ElasticSearch라는 기술을 알게됐다. 기존에는 파일 형태로 Transaction을 저장하려 했으나, 이후 주어진 Transaction을 검증하는데 있어 오랜 시간이 소모될 것 같아 해결법을 강구하던 중 알게된 기술이다. ElasticSearch는 기본적으로 REST API 통신으로 데이터를 조작할 수 있었고, 여기에 Transaction 저장방식을 객체형 DB인 MongoDB에 저장하기로 했다.
File로 저장할 때에도 JSON 타입으로 저장하여 ElasticSearch를 연계할 수 있었지만, 그냥 파일로 저장 안하고 MongoDB에 저장하기로 결정했다. (MongoDB에만 Transaction을 저장하는건 문제가 될 수 있지만, 개발하고 있는 블록체인에서는 Authenticator라는 역할이 몇명 존재하기 때문에, 여기에 약간의 분산저장을 하고 있어서 크게 신경쓰지 않기로 했다.)
Linux와 관련된 글은 많았으나, 이번에 개발하는 서버가 Windows 기반이기에 관련 자료가 거의 없다싶이 하여 글을 쓰게 됐다.
구현하고자 하는 기능은 다음과 같다. MongoDB에 어떤 데이터가 저장되면 ElasticSearch의 데이터로 동기화시켜 데이터를 구할때는 MongoDB가 아닌 Elastic Search에서 가져올 것이다.
사용된 MongoDB와 ElasticSearch 그리고 Logstash의 버전은 다음과 같다.
Logstash를 설치한 이후에, mongodb input 플러그인을 설치해줘야 하는데, 정말 쉽게 cmd로 설치할 수 있었다. (관련된 글들이 모두 linux 기반이고, 명령어 또한 linux의 그것과 닮았기에 윈도우에서 동작 안할 줄 알았는데, 된다. 이걸로 이틀은 날려먹은 것 같다.)
cmd 명령 프롬프트 창을 관리자 권한으로 실행시킨 뒤, 다음 명령어를 입력하면 logstash-input-mongodb가 설치된다.
cd \path\to\logstash\bin\logstash-plugin install logstash-input-mongodb
만약 Success to installation( 정확히 기억 나지는 않지만 )과 같이 설치에 성공했다는 문구가 안뜨면, 오류가 함께 출력되니 그에 맞춰서 대응하면 된다.
이후 logstash를 이용하여 mongodb로부터 데이터를 가져와 elasticsearch로 넘겨주는 설정이 필요하다. 해당 설정은 다음과 같다.
# Sample Logstash configuration for receiving # UDP syslog messages over port 514 input { mongodb { uri => '몽고DB 주소' placeholder_db_dir => '입력 저장할 파일 경로' placeholder_db_name => '저장할 파일 이름' collection => '가져올 collection 이르' batch_size => 2000 generateId => false parse_method => "simple" } } filter { mutate { copy => { "_id" => "[@metadata][_id]"} remove_field => ["_id"] } } output { elasticsearch { hosts => ["엘라스틱 서치 주소"] index => "데이터를 삽입할 index 명" document_id => "%{[@metadata][_id]}" } stdout { } }
batch_size: 한번에 가져올 수 있는 최대 양 이다. placeholder_db_dir에 저장된 placeholder_db_name을 지운다고 해서 Elastic Search에 동기화된 내용이 삭제되는 것은 아니다. 따라서 데이터의 삭제를 위해서는 elastic search에서 직접 제거해주어야 한다.
filter같은 경우에 엘라스틱 서치의 _id와 몽고db의 _id가 겹쳐서 오류가 발생할 수 있기 때문에, 몽고db의 _id를 나는 제거해주었다.
파일 명은 mongodb.conf 이며, 저장 위치는 logstash가 설치된 폴더의 config 폴더 내에 저장했다. ( \logstash\config\mongodb.conf\ )
이후 logstash를 실행 시켰을 때 정상적으로 실행된다면 성공이다.
사실 몽고DB와 엘라스틱 서치는 따로 건드리는 것 없이 logstash만 잘 설정해주면 작동해야만 한다. 몽고DB와 엘라스틱 서치가 정상적으로 동작하지만, sync가 안된다면 logstash의 설정에서 무엇인가 잘못된 것이니 logstash에서 찍히는 log를 잘 읽어보면 해결할 수 있을것이다.
블록체인의 작업증명은 거래(트랜잭션)이 주어지면, 해당 거래를 가지고 블록을 만들 수 있는지 확인해야 한다. 주어진 거래와 같은 블록을 이루는 거래들을 이용하여 해당 블록의 Hash값과 일치하는지 확인해야 하는데, 이 때 머클트리를 활용한다.
머클트리
머클트리는 위 이미지와 같이 생겼는데, 거래 정보는 Leaf Nodes를 구성하고, 해당 거래 정보의 부모들은 각 자식들을 Hash 한 값이 된다. 이렇게 쭉쭉 타고 올라가 결국 root값 또한 root의 자식들을 hash한 값으로 이루어진다. 또한 Merkle Tree는 생성된 후에 값이 변조되면 안되기 때문에, 오직 getRoot()라는 method만 가진다. (블록체인에서 블록의 수정은 불가능하기 때문이다.) Merkle Tree를 정말 트리로 구성하여 삽입, 수정, 삭제 등의 기능을 구현해도 되지만, 이는 Java의 자료구조에서 다룰 것이고, 오늘은 블록체인의 Merkle Tree이기 때문에 단순 삽입을 통한 merkle Tree를 구성하게 하겠다.
블록으로 만들려고 하는 상황중 가장 좋은 경우는 트랜잭션의 갯수가 2^n꼴로, 이진트리를 만들었을 때 모든 leaf노드들을 트랜잭션으로 만들 수 있을때는 가장 편하다. 받아들인 트랜잭션(거래)들을 모두 leaf 노드로 설정하고, 부모를 만들어 나가며 root값을 찾으면 되기 때문이다.
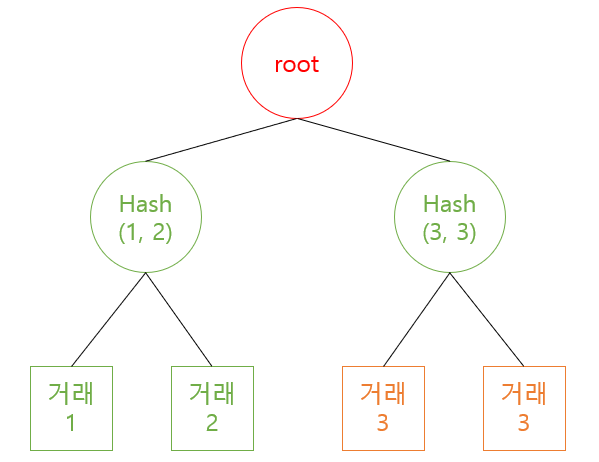
거래의 수가 홀수라면 어떻게?
내가 가지고 있는 홀수 개의 수로 머클트리를 만들어야 할때는, 간단하게 다음과 같이 해결할 수 있다.
짝이 없는 거래(마지막 홀수번째)는 자신을 이용하여 해쉬한다.
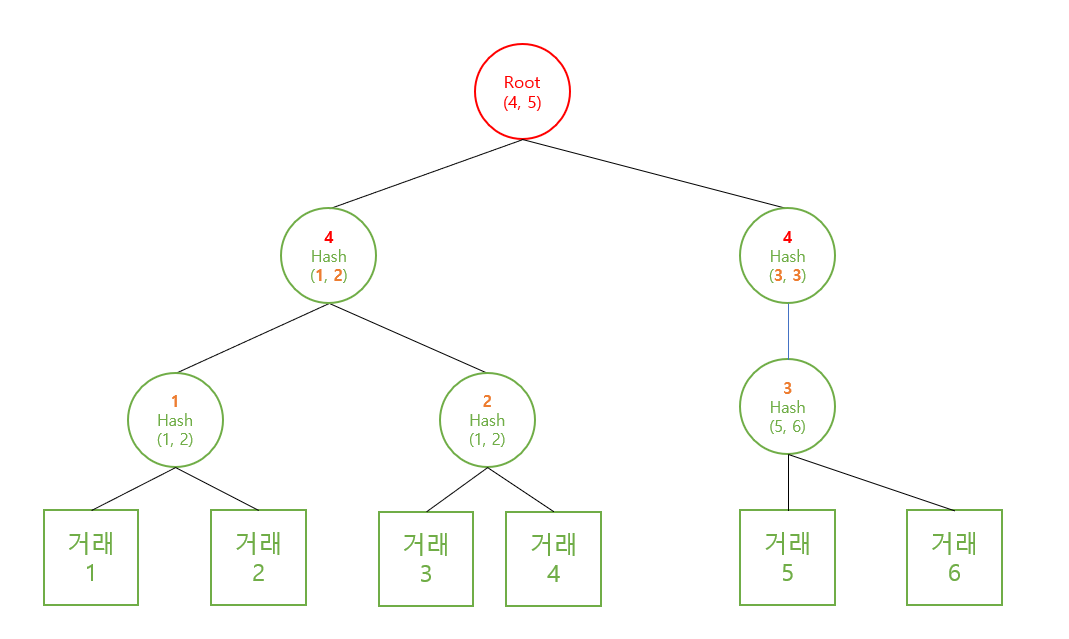
짝이 없는 거래, 마지막 홀수번째 거래의 경우에는 자기 자신을 한번 더 사용하여 해시값을 만들면 된다. 이 아이디어를 응용해 보면, 2^n꼴이 아닌, 짝수개의 트랜잭션은 어떻게 하면 될까? 다음 그림을 보고 힌트를 찾길 바란다.
짝수개 머클트리
그림상 2번 Hash가 (1, 2)라 되어 있는데 오타다. Hash(3, 4)가 2번 동그라미가 되어야 한다.
머클트리 구현 아이디어
머클트리는 Binary Tree형 자료구조이다. 그리고 실제 데이터 삽입은 단말 노드에서만 이루어진다. 즉 머클트리는 기존 트리처럼 Top-Down 형식의 구현이 아니라 Bottom-Up 형식으로 구현하면 된다. 그리고 블록체인의 각 블록은 머클트리의 루트값만 가지고 있으면 된다. 바꿔 생각해보면, 만약 블록체인이 머클트리를 이루는 모든 해쉬값을 갖고 있으면 추적할 수 있게 되는것이고, 이는 보안상 구멍이 될 수 있는 것이다. 누구든 해당 블록을 만드는 각 트랜잭션을 만들 수 있게 되고, 그를 바탕으로 누가 어떤 거래를 했는지 알 수 있게 되는 것이다. 따라서 머클트리는 각 depth간 모든 해쉬 정보를 갖고 있을 필요가 없으며, 머클트리를 검증하기 위한 각 계층의 해쉬값을 Peer들에게 요청하면 되는것이다. 다시 본론으로 돌아와서 머클트리는 따라서 Root값만 가지고 있으면 된다. 그렇기 때문에 Tree의 모든 특성을 반드시 갖고 있어야 하는것은 아니다. Bottom-Up 구현을 따라서 ArrayList를 이용해 구현해 볼 것이다.
위 사진을 보고 어느정도 이해가 가는가?
머클트리와 관련하여 어떻게 머클트리가 생겼는지 알 수 있지만, 실제로 구현하는데에는 어려움이 있을 수 있다. 이전에 작성한 ArrayList와 마찬가지로 기본 아이디어만 본 포스트에서 구현하고, 활용과 응용은 직접 하시길 바란다.
위 이미지를 보면 알겠지만, ArrayList에 거래를 집어 넣고, 2개씩 끊어 Hash를 진행하면 된다. 함수 하나로 서론에서 말한 세가지 경우를 모두 처리하는 코드를 만들 수 있지만, 세 방향 모두 나눠서 진행할 것이다. 우선 완벽히 Full Binary Tree를 이룰 수 있을때에 대한 구현 방법이다. 이 경우는 정말 쉬운데, 아래 사진에서 처럼 두개 씩 끊어 Hash를 진행하고, List의 가장 마지막에 오는 녀석이 머클트리의 Root 값이 된다.
본 코드는 정말 "아이디어의 기초"를 표현하기 위한 코드이다. depth를 구해서 얼마만큼 Hash를 진행하여야 머클트리가 완성되는지를 표현하였다. depth를 다른시각으로 보면 level이 되고, level만큼 부모를 만들어야 root가 되는지 알 수 있기 때문이다. (이진 트리는 log2n 만큼의 depth를 갖고, 따라서 getDepth 함수는 정말 수학식을 나타낸 것이다.) i가 depth부터 시작하는 이유는 bottomUp 이기 때문에, 아래에서부터 위로 만들기 위함이다. j는 현재 내가 만들고 있는 List의 사이즈를 2^depth로 나누었을때 나머지인데, 그 이유는 다음과 같다.
총 depth가 4인 트리에서, depth 2에 대해 만들기 시작했을 때, depth 3에는 데이터가 8개 존재한다.
또한 hash를 시작해야 하는 List의 인덱스는 0인데, 그 이유는 List에는 방금 막 만든 해시값들만 담겨있기 때문이다. Depth 2에 대해서 해시가 모두 끝났으면, depth 1로 올라오게 되고, 이 때 hash를 시작해야 하는 인덱스는 9이다. 이 때 List의 사이즈는 12이고, i는 2(최초 depth는 4이고, i가 2번 반복했다. 따라서 4-2=2)가 된다.
즉 12 % 4 = 8이 되고, 0~8에 존재하는 원소는 9개이기 때문에 우리가 찾고자하는 인덱스 9가 된다.
for(int j~) 부분을 보게되면, 우리가 만든 List에서 해당하는 index에 대해 Hash를 진행하고 있는것을 확인할 수 있다. if(i == 1)인 부분은, i가 1, 즉 root의 자식 노드들이 되고, 따라서 hash를 진행할 때 size -2, size -1을 통해 마지막 두 Hash값에 대해 Hash를 진행하면 Root 값이 나오게 된다.
거래가 홀수개
private String createOddRoot(ArrayList<MerkleNode<Object>> merkleNodes) { int size = 0; int depth = getDepth(merkleNodes.size())+1; System.out.println("depth: " + depth); ArrayList<String> datas = new ArrayList<String>(); datas.clear(); int start = 0; int last = merkleNodes.size(); for(int i = depth; i > 0; i--) { start = (i == depth || (i == depth-1) ? 0 : last); last = (i == depth ? merkleNodes.size() : datas.size()); for(int j = start; j < last; j += 2) { if(i == depth) { datas.add( new Crypto().doHash(merkleNodes.get(j).getData().toString() + merkleNodes.get(( (j==last-1 ? (j) : (j+1)) )).getData().toString()) ); } else { datas.add( new Crypto().doHash(datas.get(j) + datas.get( (j==last-1 ? (j) : (j+1)) )) ); } } } size = datas.size(); return datas.get(size-1); }
거래가 홀수일 때는 j의 반복자 시작과 마지막을 잘 설정해주면 된다. 홀수개에 대하여 시작 부분은 최초 트랜잭션을 받아오는 부분과, 그 다음 부분은 모두 0부터 시작하면 된다. 그 이유는 최초 List가 비어있고, 전달받은 거래들에서 데이터를 가져오기 때문이고, 최초 부모들을 만들기 성공했다면, 우리가 만든 List의 0번부터 해시를 진행해야 하기 때문이다. 그 이외의 경우에는 이전 반복자의 last값이 시작값이 되는데, 해시를 시작해야하는 인덱스 번호가 곧 지난번의 마지막 인덱스 이후이기 때문이다. 또한 해당하는 인덱스의 값은 이전 반복자에서 분명히 만들어 졌기 때문에, 이렇게 사용할 수 있는 것이다. last의 경우, 최초에는 내가 가지고 있는 거래의 수 만큼 해시를 진행해야하고, 그게 아니라면 만들어진 List의 사이즈만큼 만들어야 하기 때문이다. 중요한것은, Hash를 만들 때, 원소가 한개이냐(마지막 홀수번째 원소)만 확인하면 된다. 만약 그렇다면, 본인을 한번 더 사용하면 된다.
머클트리는 생각보다 간단하지만, 간단한 만큼 자료가 많지 않아서 어떻게 접근해야 할까 고민하는 사람이 많은 것 같다. 따라서 본 게시글에서는 머클트리는 이루는 기초적인 방향과 이를 바탕으로 한 기초적인 방법을 다루어봤다. Full Binary Tree가 아닌 짝수 개를 갖는 코드는 위에서 준 힌트와 Odd를 확인해보면 쉽게 만들 수 있다.\ 머클트리를 만드는 자세한 방법은 JAVA에서 다루도록 하겠다.