2023년 10월 채널코퍼레이션을 시작으로 나의 DevOps Engineer 커리어가 시작되었다. 많은 회사에 지원하며 채널코퍼레이션을 선택한 이유는 "세상을 편리하게 만들고 싶다"는 나의 꿈과 가장 가깝다고 생각들었기 때문이다.
이제는 면접때 얘기하진 않지만, 초등학생 때 게임 서버 개발을 통해 내가 원하는 것을 표현하고 의도한 대로 시스템이 움직이는 것은 내게 엄청난 호기심을 자극하며 동시에 매력으로 다가왔고 이때부터 개발자라는 장래희망을 정하고 언젠가 세상을 편리하게 만드는, 더 나아가 세상을 바꾸고 싶다는 꿈을 꾸게 되었다.
채널코퍼레이션은 이러한 꿈에 가장 가까운 회사였고 운 좋게도 합류할 수 있었다.
돌이켜보면 지난 3년 동안 가장 크게 변한 것은 기술이 아니라 태도였다. 신입 시절의 나는 DevOps Engineer라면 서비스를 운영하기 위해 애플리케이션이 왜 이렇게 작성되었고, 왜 해당 아키텍처로 설계되었으며, 왜 해당 기술을 사용했는지 모두 이해해야 한다고 생각했다. 그리고 좋은 시스템을 만드는 것이 곧 좋은 엔지니어라고 믿었다.
취미 생활의 개발부터 대학생이라는 전공자로서 개발은 항상 주도적으로 행했고 모르는게 있다면 이해하고 해소될때 까지 파고들었다. 이러한 지적 호기심과 '취미=직업' 이라는 엄청난 장점은 누구보다 빠르게 개발자로서 성장할 수 있는 장점이자 원동력이었고 이를 통해 청소년때는 각종 대회 입상을, 대학생때는 높은 전공 성적을 유지할 수 있었다.
이러한 장점은 커리어를 시작하고 내게 엄청난 압박으로 다가왔다. 나는 경제적 이유로 사회 경력에 단절이 생기면 안된다. 그런데 개발 회사들은 흔히 온보딩 기간이 있고, 이 기간동안 회사와 신규 취업자는 서로를 경험하고 상호 평가와 판단하게 된다.
모든 시스템을 이해하지 못한 상태에서 무언가를 해내야만 한다는 압박은 엄청났다. 그러다 보니 온보딩 기간동안 총 세 번을 DevOps 리드께 그만두겠다고 말씀드렸고, 결국 퇴사했다. 그 당시 DevOps 리드께서도 내게 "원래 그렇다. 하다 보면 알게 되고, 이는 어느 회사를 가더라도 똑같다. 유진이 알고 싶은것, 하고 싶은 것은 결국 처음부터 만들지 않으면 시간이 지나면서 자연스럽게 알게되는 것들이다. 많이 힘들다면 한 달 휴직 후 돌아오시라."고 말씀주셨다. 지금에서 돌아보면 (정확한 말씀은 기억나지 않지만) 중간 평가 때의 "지금으로도 괜찮다."는 팀원과 리드의 말씀이 나는 빈 말이 아니었다는 것을 이제서야 이해한다.
유진은 나의 당시 닉네임이다.
지금 돌아보면 당시의 나는 정말 "신입"이었다. DevOps Engineer의 역할이 무엇인지, 어디까지 고민해야 하는지조차 제대로 알지 못했다. 채널코퍼레이션에서의 경험은 내게 뼈아픈 실패로 남았다. 하지만 시간이 지나면서 당시 들었던 "하다 보면 알게 된다"는 말이 어떤 뜻이었는지 조금씩 이해하게 되었다.
채널코퍼레이션을 퇴사하고 얼마 후 대학 선배가 창업한 회사에 합류했다. 정말 운이 좋게도 해당 회사는 DevOps Engineer가 없었고, 내가 처음이라 뭐든 한다면 처음부터 구성할 수 있었다.
팀원과 커뮤니케이션, 니즈 파악, 인프라 설계 등. 채널코퍼레이션에서 이해하지 못했던 "일" 이라는 것을 하나 하나 이해하고 또 배울 수 있었다. 처음부터 만들어보니 비로소 이전에는 보이지 않던 것들이 보이기 시작했다. DevOps Engineer의 역할은 사람들과 함께 문제를 정의하고, 서비스의 흐름을 이해하며, 필요한 시스템을 만들어가는 것이라는 것에 대한 "의미"도 조금씩 알게 되었다.
두 번째 회사가 정체되면서 한 명의 인간으로서 무언가를 성취하고, 발전하고 싶다는 욕구가 커졌다. 그러던 중 다른 회사에서 면접/이직 제안을 받게 되었고, 세 번째 회사로 이직을 결심하게 되는 계기가 되었다.
재밌게도 세 번째 회사는 제안을 받은 회사가 아니다.
지금의 회사는 나의 DevOps 철학을 문화로서 어떻게 풀어낼 수 있는지, 내게 부족한 점이 무엇인지 확인할 수 있었다. 3년차라서 그런지 모르겠지만, 아직 나는 커뮤니케이션을 더 길러야한다. 기존에는 "급진파" 성향의 DevOps Engineer 였다면, 지금은 "온건파"의 성향으로 한 단계 더 성숙해 질 수 있었다.
채널코퍼레이션, 대학 선배 회사, 그리고 현재의 회사까지 나는 항상 이상적인 기술을 좇았다. 레거시는 제거해야 할 악이라고 생각했고, 언젠가 더 좋은 시스템으로 바꿀 것이라면 처음부터 그렇게 만들어야 한다고 믿었다. 하지만 여러 팀과 서비스를 경험하면서 생각이 많이 바뀌었다. 좋은 기술보다 중요한 것은 상황에 맞는 선택이었다. 비용과 기술 부채, 서비스의 규모, 그리고 함께 일하는 사람들까지 고려하며 지속 가능한 시스템을 만들어가는 것이 더 중요했다. 결국 DevOps는 도구나 프로세스가 아니라 개발, 배포, 운영 전 과정을 하나의 흐름으로 바라보고, 같은 맥락을 공유하는 사람들이 빠르게 피드백을 순환시킬 수 있도록 돕는 문화라는 생각에 도달하게 되었다. 그리고 이를 위해 플랫폼을 만들고, 조직이 더 효율적으로 움직일 수 있도록 돕는 것이 DevOps Engineer의 역할이라고 생각한다. 나쁜 레거시는 없지만 나쁜 습관은 있는 것 같다. 좋은 시스템보다 더 어려운 것은 사람이고, 시스템보다 더 오래 남는 것은 문화라는 사실을 조금씩 배우고 있다.
내가 생각하는 DevOps는 애플리케이션을 안정적으로 제공하기 위해 개발, 배포, 운영 전 과정을 하나의 흐름으로 바라보는 철학이다. 누군가는 "너무 당연한 얘기 아니냐?"고 할 수 있지만, 이를 경험하며 내 것으로 체화하고 있는 입장에서는 이보다 더 명확한 표현이 없는것 같다.
간혹 채널코퍼레이션을 퇴사한 것을 후회하지 않느냐는 질문을 받는다. 지금도 그 질문에 명확하게 답하기는 어렵다. 다만 한 가지 확실한 것은, 그 경험은 내게 엄청난 양분이 되었다는 것이다. 만약 다시 그 시절로 돌아간다고 해도, 지금의 나로 성장하지 못했다면 아마 같은 선택을 했을 것이다.
간혹 이직할 때 채널코퍼레이션에 재입사는 왜 안해봤냐는 질문을 받는데, 재입사는,, 내가 하고 싶다 해서 가능한 것도 아니고, 사실 조금은 실패라는 경험으로부터 오는 두려움도 조금은 있고,, 글쎄... 언젠가 기회가 주어진다면,,,? 그때의 나는 지금과 또 다른 생각을 하고 있을지도 모르겠다.
3년 동안 가장 크게 변한 것은 기술이 아니라 태도였다. 좋은 시스템을 만드는 것보다 더 중요한 것은 지속 가능한 시스템을 만드는 것이라는 것 그리고 지속 가능한 시스템은 결국 사람과 문화에서 시작된다는 것을 조금씩 배우고 있다.
아직도 커뮤니케이션은 어렵고 또 어렵다. 하지만 앞으로의 4년차, 5년차의 나는 더 좋은 기술보다 더 좋은 문화를 만들 수 있는 사람이 되고 싶다.
언젠가 지금의 글을 다시 읽으면 또 부족한 점이 많이 보일 것이다. 그래도 적어도 지금의 나는, 3년 전의 나보다 엔지니어로서나 한 사람으로서나 조금은 더 성장한 것 같다.
최근 AWS 환경을 운영하면서 장기적인 액세스 키를 사용하지 않고 보다 안전한 방식으로 AWS 리소스에 접근할 수 있는 방법을 고민했어요.
저는 이러한 문제를 AWS SSO를 통해 굉장히 편하고 쉽게 해결한 경험이 있어요. 그래서 회사에 입사하자 마자 추진했던게 AWS SSO 사용이었어요.
그런데 외부 제약 사항으로 인해 AWS SSO를 사용할 수 없었고, 실제로 우리와 같은 환경을 많은 회사가 겪고 있을거라는 생각을 했어요.
이러한 환경에서 어떻게 AWS API 호출을 보다 안전하게 접근할 수 있게 했는지 소개합니다.
해결하고자 한 문제
최초 회사에 입사했을 때는 AWS 환경의 자원에 접근하기 위해 Long Term Access Key를 발급하고 이를 통해 AWS API를 호출하는 형태였고, 다음의 문제를 안고 있었어요.
액세스 키를 발급하고 관리하는 것은 보안상 취약점이 될 수 있다.
키가 유출되면 언제든 AWS 리소스가 위험에 노출될 수 있다.
누군가 키를 지워버리면 그 순간 모든 것이 중단된다.
키의 주기적 교체 및 관리에 대한 부담이 크다.
이러한 문제를 해결하고자 처음에는 애플리케이션 단위로 IAM Role 및 User를 생성하고 Long Term Access key를 발급했는데 이는 최소 권한 원칙은 지킬 수 있었지만 기존의 문제점들은 해결하지 못했어요.
어떻게 할지 고민하다가 “AWS SSO만 사용할 수 있으면 쉽게 해결될텐데…”라는 생각을 했고, 이는 “💡 AWS SSO와 비슷한 사용자 경험을 줄 수 있는 시스템을 만들면 되지 않을까?” 라는 생각을 했고, 시스템을 만들기 시작했어요.
AWS SSO 그리고 AWS STS
AWS Single SIgn On
AWS SSO는 AWS 인증 센터를 통해 관리되는 여러 AWS 계정에 대해 제공하는 중앙 집중식 로그인 솔루션이에요. 단순히 AWS 콘솔에 로그인 할 수 있을 뿐만 아니라 애플리케이션에서 사용하기 위한 인증/인가도 수행할 수 있어요.
이를 통해 사용자는 회사에서 허용 및 구성한 AWS 계정, AWS 콘솔, AWS와 융합된 여러 애플리케이션에 접근할 수 있어요.
AWS 인증 센터를 기준으로 구성 조직은 AWS Identity Center를 통해 그룹 및 사용자 설정, MFA 등 로그인 관련 정책 그리고 권한 정책을 설정 할 수 있고, 회사와 사용자는 별도의 Long Term Access Key를 발급 관리할 필요가 없어요.
AWS Security Token Service
AWS STS는 짧은 수명을 가진 임시 보안 자격증명(AccessKey, SecretKey, SessionToken)을 발급해 주는 서비스에요.
호출하는 주체의 자격 증명과 조건에 따라 미리 작성되어 있는 IAM Role에 대해 사용할 수 있는 임시 토큰을 발급해요.
AWS STS를 통해 발급된 토큰은 기한이 지나면 자동 폐기되므로 장기 키를 저장·관리하는 위험을 크게 줄여 주고, 이는 보안과 관리 측면에서도 유리해요.
AWS SSO와 AWS STS의 관계
AWS SSO 콘솔에서 사용자가 로그인하면 내부적으로 STS의 AssumeRole 등을 호출하여 임시 자격 증명을 발급해요.
사용자는 이 임시 자격 증명을 바탕으로 AWS 콘솔, CLI, SDK 등에서 STS가 발급한 토큰을 로컬에 저장하고 활용할 수 있어요.
이 구조 덕분에 사용자는 긴 키를 직접 다루지 않고도, 필요한 권한을 안전하게 AWS API 호출에 사용할 수 있게 돼요.
고민한 포인트
해당 시스템을 만들때 가장 크게 고민한 포인트는 다음과 같았어요.
어떻게 해야 개발자의 귀찮음을 최소화할까?
실제로 개발자들은 AWS API를 사용하는 애플리케이션을 개발하기 위해 AWS Credential을 어떻게 구성하고 관리하는지는 그들이 궁금해 하지 않는 한 알 필요 없다고 생각했어요. 그리고 이를 설명해줌으로써 개발자들의 보안 환경에 반감이 들 수 있지 않을까? 하는 걱정도 있었어요.
토큰 만료로 인해 개발자의 애플리케이션 개발 싸이클이 중간에 끊기지 않고, 의도치 않은 버그에 빠지지 않도록 하고자 했어요. (코드는 정상인데 토큰이 만료되어서 에러가 발생하는 등)
보안이 엄격해질수록 사람의 귀찮음이 늘어나기 때문에 제가 제공하는 환경으로 인해 개발자의 업무 효율성이 떨어지는 것을 지양하고 이러한 작업을 최소화 하고자 했어요.
AWS의 Role Chaining에 따른 STS 지속 시간 문제
해당 환경을 제공하는 시스템을 ECS 부터 Lambda까지 고민했어요. ECS나 Lambda의 경우 최소의 비용으로 시스템을 구성할 수 있을거라 생각했어요.
하루 8시간 일한다면, 적어도 8번 해당 시스템에 접근하여 STS를 획득해야 하는 귀찮음이 발생해요…ㅠㅠEC2, ECS, Lambda 등에 시스템을 배포한다면 다음의 시퀀스 다이어그램과 같은 환경이 될거라 예상했어요. 이는 AWS 정책상 임시 자격을 가진 주체가 또 다른 역할을 Assume할 때, 그 유효 시간은 최대 “1시간”으로 한다는 문제점이 생겼어요. 이는 앞서 고민한 개발자의 귀찮음을 최소화 하자는 것에 위배될거라 생각했어요.
이를 해결하기 위한 웹 대시보드 서버의 코드는 다음과 같아요. EKS의 IdP Federation을 활용하여 WebIdentity를 Assume 하는 것이 주요 내용이에요.
// roleArn 사용자에 대한 Assume Role 대상이에요. 이 역할에 필요한 정책이 할당되어 있어요
func assumeWithWebIdentity(ctx context.Context, roleArn, sessionName string, duration int32) (*sts.AssumeRoleWithWebIdentityOutput, error) {
tokenFile := os.Getenv("AWS_WEB_IDENTITY_TOKEN_FILE")
data, err := os.ReadFile(tokenFile)
if err != nil {
return nil, fmt.Errorf("read token file: %w", err)
}
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
return nil, err
}
client := sts.NewFromConfig(cfg)
return client.AssumeRoleWithWebIdentity(ctx, &sts.AssumeRoleWithWebIdentityInput{
RoleArn: aws.String(roleArn),
RoleSessionName: aws.String(sessionName),
WebIdentityToken: aws.String(string(data)),
DurationSeconds: aws.Int32(duration),
})
}
EKS를 사용하고 있기 때문에, 이를 활용하여 시스템을 구성하자.
우리 회사는 어차피 EKS를 사용하고 있기 때문에 남는 자원으로 애플리케이션을 돌릴 수 있을거라 생각했고, IRSA를 활용하여 사용자 별 권한을 쉽게 융합할 수 있을거라 생각했어요.
특히 EKS의 서비스 계정은 WebIdentityFederation을 통해서 “신뢰받는 외부 자격 제공자”로 취급 받게되고, 이는 Role Chaining이 아니라 서비스 계정의 직접적인 Assume Role이 가능하다는 장점이 있어요.
AWS SSO와 같이 사용자에 대한 인증이 가능해야 한다.
저는 AWS SSO를 사용하면서 굉장히 편했던 경험이 있어요. 그래서 회사에 입사하자 마자 추진했던게 AWS SSO 사용이었어요. 그런데 외부 제약 사항으로 인해 AWS SSO를 사용할 수 없었고, 많은 회사가 우리와 같은 환경일거라 생각했어요.
이는 해당 글을 작성하는 계기가 되었답니다.
AWS SSO는 사용자의 계정과 MFA 인증을 통해 임시 자격을 할당하는데, 이처럼 해당 개발자만 알고 있는 정보를 바탕으로 사용자 인증이 가능하게끔 했어요.
회사에서 DataOps를 위해 Airflow를 구성하고, 안정적인 운영 환경을 제공해야 하는 태스크가 있었다. 요즘 같은 세상에 컨테이너 혹은 Kubernetes 차트 등을 이용하여 편하게 배포할 수 있지만, DevOps로써는 보다 많은 고민이 필요했고, 본 글은 Airflow 운영 3개월차가 작성하는 다른 누군가에게 도움이 되기를 기대하며, 또 미래의 내가 찾아 볼 수 있는 하나의 기록으로써 남기는 글이다.
Managed Workflow Apache Airflow vs EKS
SaaS 형태의 Apache Airflow를 이용하는 것은 실질적으로 Apache Airflow를 모르는 상태에서 운영하게 될것으로 예상했다.
놀랍게도 이는 SaaS를 이용하는 대다수의 이유기도 하지만, 우리 회사의 경우 데이터 사업 회사기 때문에 ETL 파이프라인을 잘 모르는 상태로 배포하는 것은… (이하생략)
또한 MWAA에 대해 찾아보니, 커스터마이징이 생각보다 까다롭고 문제가 발생했을 때 추적이 어렵다는 후기들을 보고 온프레미스로 배포하기로 결정했다.
그리고 비용…😂
Airflow의 Executor를 무엇으로 선택하는게 좋을까?
Celery Executor vs Kubernetes Executor
Celery Executor의 경우 등록된 워커의 리소스를 이용하여 워크플로우를 처리한다. 이 경우 “워커 관리”라는 관리 지점이 생기고 워커의 자원에 따라 태스크 실행이 제한될 수 있다.
N 대의 워커 운용
분산된 워커 환경에 대한 관리
워커 failover
concurrency 제한
이러한 이유로 인해 Kubernetes Executor를 선택하여 DAG를 처리하는 방안을 선택했다.
DAG 실행 시 각 Task에 대한 Pod가 생성되기 때문에,, 워커의 실패가 없다.
Cluster Autoscaler (Karpenter)를 통한 능동적인 워커 자원 관리
Airflow 환경 설정 = concurrency 설정 → 워커로 부터 자유롭다.
Kubernetes Executor, 조금 더 섬세하고 자유롭게 운영하고 싶은데..
Kubernetes Executor는 Pod Template을 통해 Task를 실행할 Pod의 스펙을 정할 수 있다. 이를 통해 목적별, 작업별, 심지어 그룹별로 Pod가 실행될 템플릿을 미리 정하고, executor_config을 통해 template을 지정하여 사용할 수 있다.
이에 따라서 Spot Instance, GPU, CPU, CPU Architecture, 그리고 자원량 까지 정할 수 있다.
Pod Template에 대해 Airflow Pool을 지정한다면, 더 멋진 관리가 가능하다.
Airflow를 Kubernetes와 이용한다면 Kubernetes Pod Operator라는 것을 접하게 되는데, 나는 사용하지 않기로 했다.
Kubernetes Pod Operator의 “격리된 실행 환경”을 보장하라는 철학에 따라 Kubernetes Executor의 작업을 처리하기 위해 생성된 Task Pod와는 별개로… 또 하나의 Pod가 생성되어 처리된다. 즉.. 하나의 Task에 두 개의 Pod가 생성된다. 이는 불필요한 자원낭비로 이어질 수 있다.
보기도 힘들고.. 심지어 둘 간의 의존성이 혹시라도 끊어진다면, 작업의 유실로 이어지기 때문에.. Kubernetes Executor만 사용하기로 했다.
그렇다고 KPO 자체에 의문을 갖는것은 아니다. 일반화 할순 없지만, 분명 더욱 세분화 해야 하는 작업이 있을것이고 이에 따라 따른 세밀한 제어가 필요할 때 사용할 수 있다.
컨테이너에 대해 공부를 해야겠다는 생각, 그리고 숙제로 미루어 왔던 Control Group에 대해 공부하자는 계획을 세운 뒤 꽤나 오랜 시간이 흘렀습니다. 링크드인의 글을 눈팅하던 중 우연히 “쿠버네티스가 쉬워지는 컨테이너이야기 시리즈” 게시글을 보게 되었고, 해당 글을 바탕으로 공부를 시작했습니다.
앞으로 작성할 cgroup 관련 게시글은 해당 글을 바탕으로 컨테이너에 대한 이해도를 높이고자 작성한 글 입니다.
컨테이너가 리눅스의 union filesystem, cgroup, namespace를 이용해 만들어지는 것을 알고 있는 사람
cgroup이 단순히 자원을 격리한다는 것만 알고 있는 사람
본 글의 마지막 부분에는 천강진 님의 이번 글의 대상이 아닌 독자에 대한 개인적인 견해를 작성해 놓았습니다.
컨테이너
컨테이너는 리눅스의 union fs (overlayfs), cgroup, namespace를 이용하여 host os의 메인 워크로드와 격리된 워크로드를 제공하는 가상화 솔루션입니다.
union filesystem을 이용하여 애플리케이션을 실행하기 위한 운영체제 환경부터 시작하여 서비스 바이너리까지 레이어로 나뉘어진 하나의 통합된 파일 시스템을 제공하여 언제 어디서든 동일한 환경을 제공하고 namespace를 이용하여 애플리케이션 프로세스를 격리하여 독립된 환경을 제공할 수 있다면,
control group은 이렇게 격리된 환경, 그리고 언제나 동일한 애플리케이션을 실행하기 위한 리눅스 프로세스 그룹에 시스템 자원을 격리, 할당하여 제어할 수 있도록 해 줍니다.
정리하자면,
Union Filesystem을 통해 low layer, upper layer, merged view를 통해 레이어화 된 애플리케이션 실행에 필요한 파일시스템을 제공하고
Namespace를 통해 애플리케이션의 실행 환경을 분리하며
Control Group을 통해 애플리케이션 실행에 필요한 하드웨어 자원을 격리, 제한하여 독립된 환경에서 안정적으로 실행될 수 있도록 하는 가상화 기술입니다.
“천강진”님의 시리즈를 읽으면서 Control Group을 이해한다면 컨테이너 환경에서의 안정적으로 하드웨어 자원을 제공할 수 있을 뿐 아니라, 애플리케이션에 어떤 현상 혹은 문제가 발생했을 때 조금 더 넓은 각도에서 원인을 분석하고 문제를 해결할 수 있을 것이라 느꼈습니다.
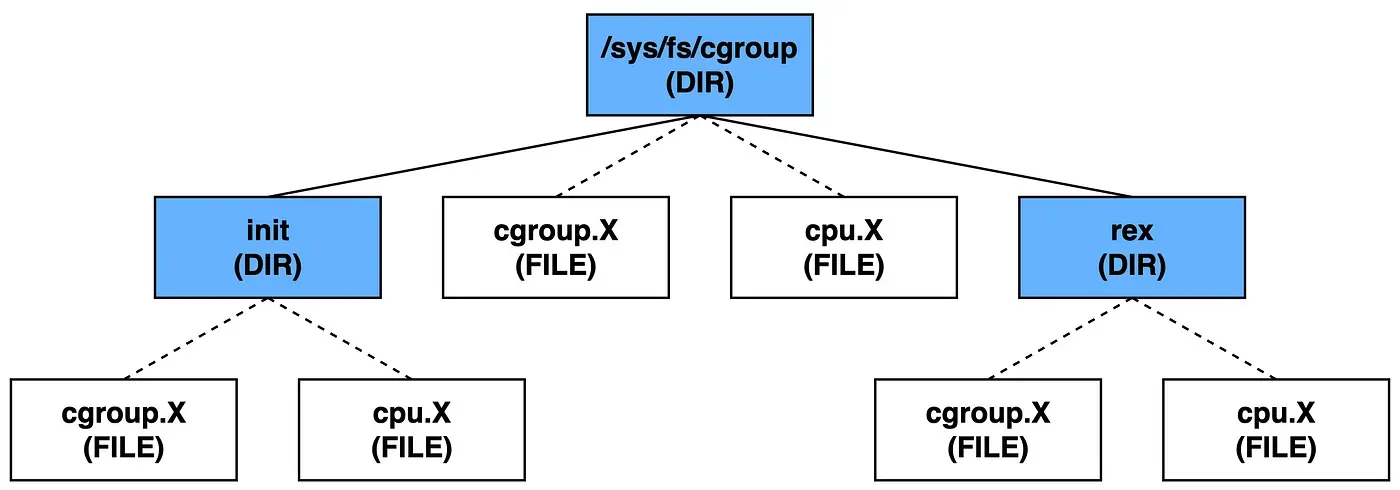
Control Group은 /sys/fs/cgroup 아래에 논리 제어 그룹을 확인할 수 있으며 루트 제어 그룹 아래에 자식 제어 그룹이 존재하는 형태입니다. 새로운 논리 그룹을 생성하려면 대상의 루트, 혹은 자식 제어 그룹에 폴더를 생성하면 됩니다.
출처: 쿠버네티스가 쉬워지는 컨테이너 이야기 — cgroup, cpu편, 천강진님
A라는 논리 그룹을 새롭게 만들 경우, 리눅스 시스템에 의해 해당 디렉토리 아래에 자동으로 다음과 같은 구조가 추가됩니다.
단순히 논리 그룹을 만듦으로써 프로세스 격리된 제어 그룹 공간을 활용하는 것은 아닙니다. 생성된 제어 그룹에 실행중인 프로세스의 ID를 할당함으로써 실질적인 제어 그룹을 이용하게 됩니다.
물론 아직 제어 그룹에 대해 자원에 대한 제한을 설정하지 않았기 때문에 아직은 루트 제어 그룹을 그대로 따르는 상태입니다.
Docker의 Control Group과 CPU
잠깐! macOS의 경우 /sys/fs/cgroup을 찾을 수 없습니다. 아래의 명령어를 통해 host의 /sys/fs/cgroup을 확인할 수 있는 컨테이너를 실행해 주세요.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b1a5dc151e15 justincormack/nsenter1 "/usr/bin/nsenter1" 3 minutes ago Up 3 minutes cgroup-host
e1277fe09be5 docker:27.3.1-dind-alpine3.20 "dockerd-entrypoint.…" 7 minutes ago Up 7 minutes 2375-2376/tcp cgroup
5d16df9b31de mysql:8.0 "docker-entrypoint.s…" 4 days ago Up 7 minutes 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp mysql
ba834863df92 redis:7.4 "docker-entrypoint.s…" 4 days ago Up 7 minutes 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp redis
우리가 생성한 예제의 경우 e1277fe09be5로 실행되고 있는 것을 확인할 수 있으며, 현재 아무 자원 제한을 두지 않았기 때문에 cpu의 max, 가중치를 Host OS에서 확인해 봤을 때 모두 기본 값임을 확인할 수 있습니다.
control group에서, 다시 말해 컨테이너에서 cpu 자원을 제한한다는 의미는 CPU 스케줄링에 있어서 얼만큼 자원을 선점할 수 있느냐를 의미하는데, 다시 말해 --cpus 0.5를 설정하는 행위는 100ms 동안 50ms를 선점할 수 있다는 것을 의미하게 됩니다.
해당 부분이 이해되지 않으신다면, 운영 체제의 CPU 스케줄링에 대해 찾아보시면 좋을것 같습니다.
만약 1개를 넘어가면 어떻게 될까요? 간단하게 하기 위해 cpu 개수를 2로 할당한다면, 다음과 같은 결과가 나오게 됩니다.
실제 애플리케이션이 동작하는 환경은 다수의 CPU를 가지는 환경이기 때문에, 단일 CPU의 환경이 아닌 이상 여러 CPU를 통해 각각 100%를 선점하여 200ms를 달성하게 됩니다.
그렇기 때문에 컨테이너 플랫폼 혹은 오케스트레이션 환경에서 cpu 자원을 요청하거나 제한할 때 실제 cpu의 core 수를 넘어서 요청할 수 없게 됩니다.
쿠버네티스의 cpu.weight (cpu.shares)
cpu.weight은 control group을 통해 생성하는 프로세스의 cpu 가중치를 설정할 수 있습니다. 일반적으로 도커, crio 등 컨테이너 플랫폼 환경을 실행한다면 cpu.weight은 일반적으로 100으로 설정되는 것을 확인할 수 있습니다. 이 경우 “천강진”님의 예제를 통해 cpu.weight을 쉽게 이해하실 수 있습니다.
하지만 실제 컨테이너 오케스트레이션 환경(쿠버네티스 등)이나 SaaS, PaaS로 제공되는 환경의 경우 cpu.weight 값이 100으로 설정되어 있지 않는 경우도 있는데, 이 경우 실행하는 서비스 혹은 환경에 의해 cpu.weight 값이 계산되어 할당됩니다. 이는 실제 CPU 리소스를 할당할 때 상대적인 CPU 우선순위를 설정하는 cpu.weight의 특징이자 영향을 받았기 때문입니다.
아래는 온프레미스 환경에 쿠버네티스를 설치하고 제어 그룹 디렉토리로 이동했을 때의 상태입니다. 아직 아무 파드도 설치하지 않았으며, crio v1.31과 쿠버네티스 1.31.2를 설치한 직후의 상태입니다.
쿠버네티스의 경우 cpu.weight의 값이 79인 이유는 Control Group V1에서 V2로 넘어오면서 cpu.shares를 cpu.weight로 변환하는 과정에서 스케일링이 발생했기 때문입니다.
cpu.shares는 실질적으로 가중치를 할당하여 사용한다기 보다 cpu.shares가 설정된 제어 그룹 간의 비율을 바탕으로 CPU 자원을 나눠 사용할 수 있게 됩니다. 즉 cpu.shares가 512, 1024, 2048로 설정되어 있다면, 1:2:4의 비율로 cpu 자원을 할당받아 사용할 수 있게 됩니다. cpu.shares의 최대 값은 2^18 - 2인 262142를 갖습니다.
control group v1 에서 cpu.shares는 최대 값은 이론상 2^32를 갖지만, 시스템의 안정성 등을 위해 최대 값을 2^18로 제한하고 있습니다.
실제로 Ubuntu 등 Linux 계열의 cpu.shares의 옵션을 보면 [2, 262144] 값을 가지고 있습니다.
2를 빼는 이유는 cpu.shares의 최소값인 2를 보장하기 위함입니다.
512, 1024, 2048 등 vCPU에 대해 Timeslice가 2의 배수로 표현되는 이유는 Linux CFS에서 1024 = default nice 0에 대응하는 값이고, 이를 기본 CPU Weight로 사용하는데 Container의 선구자(?)인 Docker가 이 값을 채택했고 Linux Kernel, CGroup 과 동일하게 유지할 수 있습니다.
이러한 cpu.shares를 [1, 10000]의 범위를 갖는 cpu.weight로 변환하기 위해서는 다음의 식이 사용됩니다.
위 yaml을 바탕으로 pod를 배포하게 되면 cpu.weight의 값은 얼마가 될지 한번 고민해 봅시다.
우리는 전체 CPU shares인 2048에 대해 250m을 요청했고, 2개의 코어를 갖는 노드에서 CPU Weight는 79를 갖고 있습니다. 즉 250 / 2048 만큼 요청했고, 79의 가중치를 갖기 때문에 다음과 같은 식을 갖는다고 예상할 수 있습니다.
1 + 250 / 2048 * 79 ~= 9.6 (10)
이를 직접 워커 노드의 /sys/fs/cgroup을 통해 확인해봅시다.
root@worker1:~# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
**8a6b6f7c79ece 27a71e19c95622dce4d60d4a3760707495c9875f5c5322c5bd535214799593ce 29 minutes ago Running busybox 0 c063f7c199d23 a**
9f61aea39bdf1 registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 fb79be5137b43 coredns-7c65d6cfc9-k65k4
89986ea9962fa registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 220bc9ce4e46f coredns-7c65d6cfc9-hrx2k
f34df68b00d35 registry.k8s.io/kube-proxy@sha256:22535649599e9f22b1b857afcbd9a8b36be238b2b3ea68e47f60bedcea48cd3b 13 hours ago Running kube-proxy 0 90179e9aaf2f6 kube-proxy-mb9f7
root@worker1:~# crictl inspect 8a6b6f7 | grep "pid"
"pid": 16120,
root@worker1:~# find /sys/fs/cgroup -name cgroup.procs -exec grep -H 16120 {} \\;
/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod10e59c76_03e0_447b_bbc0_d66f7ffe0583.slice/crio-8a6b6f7c79ece337d02b1ebdf1fe7984d18c2bb829aa2c75cfed19e18e166fbc.scope/container/cgroup.procs:16120
root@worker1:~# cd /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod10e59c76_03e0_447b_bbc0_d66f7ffe0583.slice/crio-8a6b6f7c79ece337d02b1ebdf1fe7984d18c2bb829aa2c75cfed19e18e166fbc.scope
root@worker1:/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod10e59c76_03e0_447b_bbc0_d66f7ffe0583.slice/crio-8a6b6f7c79ece337d02b1ebdf1fe7984d18c2bb829aa2c75cfed19e18e166fbc.scope# cat cpu.weight
10
우리가 계산한 9.6 + 1 = 10.6에 대한 10의 값이 정상적으로 출력되는 것을 확인할 수 있습니다.
혹시 모르니 resources.requests.cpu를 500m으로 설정하고 다시 확인해 봅시다.
root@master1:~/k8s/pods# cat a.yaml
apiVersion: v1
kind: Pod
metadata:
name: a
namespace: default
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
resources:
requests:
cpu: 500m
restartPolicy: Always
nodeSelector:
kubernetes.io/hostname: worker1
root@master1:~/k8s/pods# kubectl apply -f a.yaml
pod/a created
---
root@worker1:~# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
**1618ac0f6157d 27a71e19c95622dce4d60d4a3760707495c9875f5c5322c5bd535214799593ce 18 seconds ago Running busybox 0 cfbb9f68873cf a**
9f61aea39bdf1 registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 fb79be5137b43 coredns-7c65d6cfc9-k65k4
89986ea9962fa registry.k8s.io/coredns/coredns@sha256:f0b8c589314ed010a0c326e987a52b50801f0145ac9b75423af1b5c66dbd6d50 13 hours ago Running coredns 0 220bc9ce4e46f coredns-7c65d6cfc9-hrx2k
f34df68b00d35 registry.k8s.io/kube-proxy@sha256:22535649599e9f22b1b857afcbd9a8b36be238b2b3ea68e47f60bedcea48cd3b 13 hours ago Running kube-proxy 0 90179e9aaf2f6 kube-proxy-mb9f7
root@worker1:~# crictl inspect 1618ac0f | grep "pid"
"pid": 16906,
"type": "pid"
"pids": {
root@worker1:~# find /sys/fs/cgroup -name cgroup.procs -exec grep -H 16906 {} \\;
/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod089ebf2e_1909_430e_aad6_14f1ff19455b.slice/crio-1618ac0f6157df7b07558d8507856af3a5707cb941ef923786bd8d09ba259b4b.scope/container/cgroup.procs:16906
root@worker1:~# cd /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod089ebf2e_1909_430e_aad6_14f1ff19455b.slice/crio-1618ac0f6157df7b07558d8507856af3a5707cb941ef923786bd8d09ba259b4b.scope
root@worker1:/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod089ebf2e_1909_430e_aad6_14f1ff19455b.slice/crio-1618ac0f6157df7b07558d8507856af3a5707cb941ef923786bd8d09ba259b4b.scope# cat cpu.weight
20
예상값: 1 + 500 / 2048 * 79 = 20.28 ( 20 )
실제값: 20
450m → 18 (17.35 + 1)
이번 글의 대상이 아닌 독자
k8s는 왜 CPU를 압축 가능한 자원으로 보는가?
CPU Core에 대한 실행시간, 즉 스케줄링에 대해 가중치를 바탕으로 할당하기 때문에 탄력적으로 조절 가능하기 때문.
쿠버네티스에서 CPU requests/limits는 어떤 의미인가?
CPU requests는 cpu weight을 기반으로 “상대적으로” 컨테이너가 보장받을 수 있는최소 CPU 자원을 설정한다.
예를 들어, 전체 가중치가 100일 때 두 애플리케이션에 각각 50의 가중치가 설정되면, 각 애플리케이션은 최소 50%의 CPU 시간을 보장받는다.
하나의 애플리케이션만 존재할 경우, 우리가 알고 있는 스케줄링 정책과 같이 자원을 더 많이 사용할 수 있다.
만약 50의 가중치를 가진 애플리케이션이 세 개 존재한다면, 피크 타임에 모두 50%의 CPU를 요청하여 병목 현상이 발생할 수 있다.
하지만 쿠버네티스는 스케줄링 정책에서 세 번째 Pod를 Pending 상태로 유지한다.
CPU limits는 컨테이너가 사용할 수 있는 최대 CPU 시간을 의미한다. CPU 사용량은 이 limits을 초과할 수 없다.
그렇기 때문에 쿠버네티스 환경에서는 CPU requests만 설정해도 충분한 경우가 많다.
이는 전체 가중치 중 각 애플리케이션의 requests 비율에 따라 CPU 시간이 할당되기 때문이다.
따라서 limits을 불필요하게 설정하여 애플리케이션에 인위적인 병목 현상을 만들 필요는 없다.
어차피 각 비율에 따라 가질수 있는 최대 CPU 타임은 정해져있다.
다만 쿠버네티스의 QoS 정책에 따라 Guaranteed로 사용하기 위해 limits을 설정하는게 좋다.
컨테이너의 CPU 사용률은 어떻게 측정되는가? ( by 천강진 님 )
/sys/fs/cgroup/C # cat cpu.stat
usage_usec 0 # CPU 총 사용 시간(마이크로초 단위)
user_usec 0 # 사용자 모드에서 실행된 시간
system_usec 0 # 커널 모드에서 실행된 시간
### 아래 값은 cpu.max에 MAX(QUOTA)가 설정된 경우 증가
nr_periods 0 # 스케줄러에 의해 CPU가 할당된 횟수
nr_throttled 0 # 사용 가능한 CPU 시간을 초과 또는 남은 시간이 부족하여 쓰로틀링에 걸린 횟수
throttled_usec 0 # 쓰로틀링 걸린 시간
### 아래 값은 cpu.max.burst가 설정된 경우 증가
nr_bursts 0 # CPU 버스트 모드로 전환된 횟수
burst_usec 0 # 버스트 모드에서 사용한 시간
클라우드는 보안이 매우 중요한 환경인데요, 오늘은 Google Cloud Platform에서 관리중인 여러 프로젝트간 서비스 접근을 어떻게 구성하는지 공유하려 해요.
클라우드는 서비스로 제공하는 XaaS에 대한 접근을 제어할 수 있도록 IAM을 제공하는데 AWS, GCP와 같은 거대 클라우드는 IAM Role for Service Account(IRSA)라 불리는 메커니즘을 통해 더 세밀한 제어를 가능하게 해요.
이름에서 유추할 수 있듯이 서비스 계정을 위한 IAM 역할을 부여함으로써 그 메커니즘이 동작해요.
GCP의 서비스에 등록된 Service Account는 구글의 메타데이터 서버를 통해 자격 증명에 접근하고, 필요한 토큰을 관리해요.
이전에 작성한 Github과 같이 GCP 외부에서 접근하는 경우에는 Security Token Services를 통해 단기 자격을 증명해주는 토큰을 발급받아야 하고, 이 때 roles/iam.serviceAccountTokenCreator과 같은 역할이 추가로 필요해요.
GCP는 구조를 계정 수준 리소스부터 서비스 수준 리소스로 나누어 관리할 수 있는데, 베스트 프랙티스로 GCP 내부에 생성할 그 구조를 회사의 조직 구조와 일치하게 만드는 것을 권장해요.
Bucket B에서 행할 작업에 따른 Storage 접근 권한, roles/storage.objectViewer
💡 roles/iam.serviceAccountUser의 경우, 특정 사용자 혹은 서비스 계정이
bucket-sa와 같이 IAM 역할을 갖는 서비스 계정으로 가장(impersonate)해야 할 때 필요해요.
이 경우에는 Application에 부착된 서비스 계정이 직접적으로 사용하기 때문에 필요하지 않아요.
여기까지 수행하고 나면 RBAC이 구성되고, Application A에서 Bucket B에 정상적으로 접근할 수 있어요.
그런데 만약 Project B에 Bucket B 말고 여러 버킷이 존재한다며면, bucket-sa 서비스 계정을 이용해서 모든 버킷에 접근 가능하게 돼요. 이는 보안상 매우 취약한 설정이며, 따라서 Attribute Based Access Control(ABAC)을 구성해야 해요.
ABAC은 이름에서 유추할 수 있듯 속성 기반의 접근 제어 메커니즘이에요. 기존의 bucket-sa 서비스 계정은 역할을 기반으로 Bucket B에 접근 가능하도록 구성했다면, 여기에 속성을 추가하여 더 세밀한 제어를 할 수 있어요.
우리에게 필요한 세밀한 제어는 다음과 같아요.
Bucket B에 접근할 수 있어야 한다.
Bucket B 내부의 오브젝트를 볼 수 있어야 한다.
Bucket B 내부의 디렉토리 구조를 볼 수 있어야 한다.
이를 해결하기 위해 GCP는 IAM 역할에 조건을 설정할 수 있고, 역할의 조건에 필요한 리소스 유형과 리소스 이름은 다음 링크에서 확인할 수 있어요.
# 허용할 서비스 계정
member = "bucket-sa@project-a.iam.gserviceaccount.com"
# 허용할 역할
roles = [
"roles/storage.objectViewer",
]
# 역할 + 대상 = 서비스 계정이 접근할 수 있는 대상
target_resources = [
# 버킷의 이름이 bucket-b와 같아야 한다.
{
type = "storage.googleapis.com/Bucket",
name = "projects/_/buckets/bucket-b"
option = "equal"
},
# 접근하고자 하는 오브젝트는 bucket-b의 objects여야 한다.
{
type = "storage.googleapis.com/Object",
name = "projects/_/buckets/bucket-b/objects/"
option = "startsWith"
},
# 접근하고자 하는 폴더는 bucket-b의 관리형 폴더여야 한다.
{
type = "storage.googleapis.com/ManagedFolder",
name = "projects/_/buckets/bucket-b/managedFolders/"
option = "startsWith"
}
]
버킷 뿐만 아니라 다른 XaaS에 대한 접근이 필요할 때도 위와 같이 서비스 계정을 구성한다면 프로젝트간 IRSA를 구성할 수 있어요.
오늘은 초기 스타트업인 회사에서 CI/CD 파이프라인을 도입하고 이에 대한 정책 결정에 대한 고민과 솔루션을 공유하려 해요.
우선 제가 입사하기 전까지 회사는 데브옵스 엔지니어가 없었기에 CI/CD 파이프라인 마찬가지로 없었고, 클라우드 내에 딱히 정해진 정책 없이 애플리케이션을 운영중하고 있었어요. 그렇기 때문에 현재 운영중인 애플리케이션의 버전을 알 수 없었고, 언제 어떻게 배포되었는지 추적하기 어려운 환경이었어요.
이러한 환경에서 제가 CI/CD 파이프라인을 도입하기 위해 회사의 현재 상황을 분석하고 마련한 예비 요구사항은 다음과 같아요.
Continuous Integration, Continuous Delivery, Continuous Deploy 각 단계에서 현재 상태와 결과를 알 수 있어야 한다.
현재 운영중인 애플리케이션의 버전과 상태를 알 수 있어야 한다.
자동화된 시스템을 통해 개발자는 CI/CD를 수행할 수 있어야 한다.
기존에는 CI ~ Deploy까지 한 번에 무조건 실행되어서 애플리케이션의 테스트 없이 곧바로 Production에 올라가는 문제가 있었어요. 이를 해결하기 위해 “적절한 자동화”를 통해 각자가 담당한 애플리케이션을 관리, 배포할 수 있게 하고자 했어요.
DevOps Engineer를 제외한 개발자는 CI/CD 각 단계가 어떻게 진행되는지 몰라도 된다.
DevOps Engineer가 생긴 만큼 개발자는 각자의 영역에 충실할 수 있게끔 하고자 했어요.
Git Ops와 융합되어야 한다.
회사에서 GitHub Enterprise를 이용중이었고, 따라서 GitOps와 융합하고자 했어요.
1, 2번을 묶어서 기존 시스템의 가장 큰 문제점인 현재 운영중인 애플리케이션의 버전을 알 수 없는 점과 각 단계에서의 결과와 상태를 앎으로써 배포 후보군이 되는 애플리케이션이 어떤 내용을 갖는지 추적할 수 있게 하고자 했어요.
GCP Artifact Registry에 대한 Git Actions 접근 허가하기
GCP의 경우 워크로드 아이덴티티 제휴(Workload Identity Federation)를 통해 외부 서비스와의 융합을 지원하는데요, Git Actions에서 GCP에 접근 또한 이를 활용하여 해결할 수 있어요.